
Unwissentlich verursachte Fehler sind unangenehm, aber vermeidbare Fehler sind noch viel unangenehmer. Trotzdem wird erstaunlich wenig für die Fehlerprävention getan.
Kosten sollten dabei keine wirkliche Rolle spielen, sind Sie doch noch verhältnismäßig gering. Anders sieht es aus, wenn erst mal ein Fehler eingetreten ist, dieser kann nämlich sehr schnell recht teuer werden. Doch bevor wir auf die Prävention eingehen können, sollten wir uns erst einige schwerwiegende SEO Fallen, Fehler und hinterlistige negative SEO Maßnahmen ansehen.

Der Klassiker
Ich erinnere mich da an einen ganz traurigen Fall, indem ein neuer Kunde völlig verzweifelt an uns herangetreten ist. Er klagte darüber, dass seine aktuelle SEO Agentur ihn einfach nicht aus einer bestehenden Google-Abstrafung herausbekommen würde. Schon seit über 6 Monaten hätte keine der durchgeführten Maßnahmen, auch nur ansatzweise einen Erfolg gezeigt. Als Konsequenz daraus wurde Ihm nahegelegt, sich eine neue Domain zuzulegen, damit die Seite wieder bei Google mitspielen dürfe.
Der Kunde wollte aber doch lieber nochmal auf Nummer sicher gehen, und sich über uns eine zweite Meinung einholen. Bereits 10 Minuten später, konnten wir Ihm die Lösung des Problems nennen. Diese war aber noch trauriger, als bisher angenommen…
Damals wurde eine Sitemap erstellt, welche nun in der Robots.txt hinterlegt werden sollte. Doch die Robots.txt war noch nicht vorhanden. Also wurde eine neue erstellt, welche aber einen kleinen Fehler enthielt (Siehe Beispiel unten). Mittlerweile sind solche Fehler schon zum Agenturklassiker geworden.

Beispiele:
Falsch, außer wir möchten eine Indexierung der Webseite komplett verhindern:
Hier wird hinter “Disallow:“ ein Slash “/“ gesetzt. Das hat zur Folge, dass die komplette Website von der Indexierung ausgeschlossen wird.
User-agent: *
Disallow: /
Richtig:
Hier wird hinter “Disallow:“ kein Slash gesetzt. Somit kann der Crawler alle Webseiten indexieren.
User-agent: *
Disallow:
Diese oder ähnliche Fehler treten leider häufiger auf, als gedacht.
Die diebische Elster
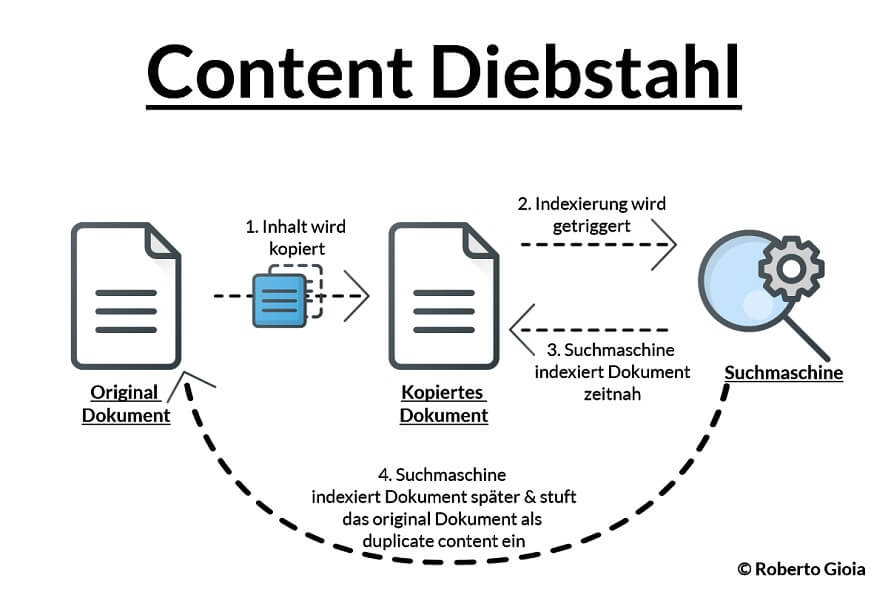
Google ist (besonders bei kleineren Seiten) nicht immer direkt in der Nähe, um einen neu angelegten Inhalt zu indexieren. Findige Content-Diebe machen sich diesen Umstand gerne zu Nutze. Sobald ein neuer Artikel online geht, wird dieser vom Content-Dieb gescraped und auf seine eigene Webseite gepackt. Darauf wird für den Artikel (über verschiedene Methoden), so schnell wie möglich eine Indexierung angefordert/ausgelöst. Nun fragen sich einige, wie es sein kann, dass jemand so schnell überhaupt feststellen kann, dass ein neuer Artikel online gegangen ist? Na indem sie z.B. die Sitemap oder den RSS Feed in automatischer Beobachtung halten. 😉
Dadurch gestaltet sich auch die Fehlersuche ziemlich schwierig. Man muss schließlich erst einmal auf die Idee kommen, seinen Content im Netzt nach Duplikaten abzusuchen. Das geht aber mit Tools wie Copyscape oder KarlsCORE zum Glück ziemlich schnell.
Canonical
Was kann hier nicht alles falsch gemacht werden?! Doch gehen wir einfach mal die häufigsten Fehler durch:
Relativer oder absoluter Pfad
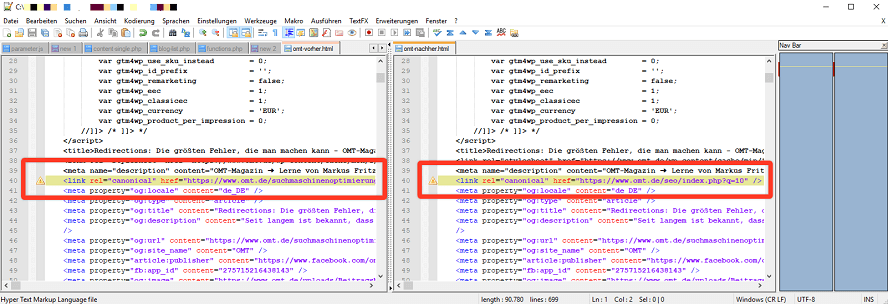
In einem Canonical-Tag kann ein relativer oder ein absoluter Pfad angeben werden. Relative Pfade sind dafür allerdings vollkommen ungeeignet. Warum? Na weil sich der relative Pfad immer auf die aktuell genutzte Domain bezieht. Ändert sich die Domain oder ist die Domain aus irgendwelchen Gründen (z.B. fehlende Weiterleitung) über eine andere Domain abrufbar, entsteht dadurch duplicate content + maximale Verwirrung für die Suchmaschine. Genau das, möchten wir ja eigentlich mit dem Einsatz des Canonical Tags vermeiden und nicht noch verstärken.
Es sollte also immer der absolute Pfad angegeben werden. Dabei ist auch darauf zu achten, dass der komplette Pfad (z.B. https://www.testdomain.de/uri.html) angegeben wird. Nur die Domain (z.B. www.testdomain.de/uri.html) anzugeben, ist übrigens auch falsch.
Falsch 1 – Relative Pfadangaben:
<link rel=”canonical” href=”/uri.html” />
Falsch 2 – Angaben ohne Protokoll:
<link rel=”canonical” href=”www.testdomain.de/uri.html” />
Richtig:
<link rel=”canonical” href=”https://www.testdomain.de/uri.html” />
Der Programmierer hat es doch nur gut gemeint
Damit sich manche Kunden nicht so viel Arbeit mit lästigen Canonicals machen müssen, greifen viele Entwickler auf eine teilautomatisierte Lösung zurück. So wird z.B. jede URL automatisch auf sich selbst referenziert, sofern keine URL manuell hinterlegt wurde. Im Grunde genommen eine super Idee, sofern sie richtig umgesetzt wurde. Hier wird oft der folgende Fehler gemacht: Die aktuell aufgerufene URL (teilweise oder auch komplett) wird über ein Skript ausgelesen und in den Canonical-Tag geschrieben. Hier haben wir erneut das Problem, dass sich bei Änderung der Domain auch der Canonical-Tag wieder verändert.
Hier ein konkretes Beispiel, welches Problem damit auftreten kann:
Manche Server lassen sich z.B. über ihre IP-Adresse oder (im Fall von z.B. All-inkl.com) über eine alternative Setup-Domain aufrufen. Somit würde eine eingerichtete 301 Weiterleitung in der .htaccess Datei also nicht für die Setup-Domain oder die IP-Adresse greifen. Ergo: Gelangt diese Domain irgendwie in den Index, entstehen doppelte Inhalte und das Canonical trägt durch seine Falschkonfiguration nicht zur Lösung des Problems bei.
Hinweis: Ein ähnliches Problem kann übrigens auch mit selbstreferenzierten Parameter-URLs auftreten. Es gilt deshalb immer, die Canonicals auf solche Schwachpunkte hin zu untersuchen.
JavaScript und Google! (JavaScript Browser Redirection)
Wenn hier nicht aufgepasst wird, kann es zu fatalen Fehlern kommen.
Hier eine kleine Geschichte dazu: Irgendwann 2015/2016 hat Google eine Änderung am Crawler und/oder dem Indexierungsprozess vorgenommen. Google kann seit diesem Zeitpunkt automatische Browser-Länderweiterleitungen (per JavaScript), mehr oder weniger gut interpretieren. Leider setzt es alle Weiterleitungen nur noch auf die englische Variante (zumindest war es in diesem beschriebenen Fall so). Das wirklich Schlimme daran ist, dass dadurch fast alle anderen Länderversionen der Webseite deindexiert wurden. Und das in einer rasenden Geschwindigkeit. Das tückische daran: Die Weiterleitung funktioniert auf der Webseite einwandfrei. Man kommt also erst mal gar nicht auf die Idee, dass es etwas mit der automatischen Browser-Weiterleitung zu tun haben könnte. Zudem gab es auch vorher keine Probleme damit. Erst als wir uns die verbleibenden Rankings in den SERPs angeschaut haben, ist uns aufgefallen, dass größtenteils nur die englischsprachigen Metadaten angezeigt wurden. Darauf haben wir die automatische Länderweiterleitung ausgeschaltet und siehe da, die Rankings kamen langsam aber beständig wieder zurück. Dieses Problem ist uns in der Zwischenzeit auch schon öfters vorgekommen, denn mit dem beliebten WordPress Plugin WPML wird diese Option (ohne Warnhinweise) mit angeboten. Ein kleiner Hinweis würde hier bestimmt nicht schaden.
Noindex != Nocrawl
Teuer kann es auch werden, wenn wir mit dem Crawlbudget bezahlen müssen. Möchte wir nicht, dass eine Seite im Google-Index landet, so zeichnen wir den Content mit dem robots“noindex“ tag aus. Das bedeutet aber noch lange nicht, dass Google die Seite nicht doch crawlt. Möchten wir wirklich Crawlbudget für wichtigere Seiten aufsparen, gibt es bisher nur zwei bis zweieinhalb vernünftige Lösungen. 😉
- Seiten oder Verzeichnisse über die Robots.txt vom Crawling ausschließen
- PRG Patterns einsetzen
- Über die Parameterbehandlung der Google Search Console: Darüber können wir Google auf die Behandlung bestimmter Parameter hinweisen. Aber immer im Hinterkopf behalten, dass es sich hierbei nur um einen Vorschlag und keine Anweisung für Google handelt.
Denkt bitte daran, dass dadurch auch kein “follow“ (zumindest ganz sicher bei Punkt 1 und 2) mehr möglich ist. Die Seite wird nicht mehr gecrawlt oder indexiert. Somit kann auch automatisch keinen Links mehr gefolgt werden.
Der absolut größte SEO Fehler
Trommelwirbel: SEO als alleinigen Kanal zu nutzen und dabei nur auf ein einziges Suchsystem (welches meistens Google ist) zu setzen. Begeben wir uns vollkommen in die Arme von nur einem Suchsystem, sind wir auch von diesem vollkommen abhängig. Schon eine minimale Änderung im Algorithmus kann dazu beitragen, dass die eigene Seite nicht mehr so relevant erscheint, oder die ausgesendeten Signale als “spamig“ eingestuft werden. Dabei spielt es auch keine Rolle, ob es wirklich so ist. Das Suchsystem entscheidet, was richtig oder falsch ist. Das hat schon etliche Unternehmen in Bedrängnis gebracht oder im schlimmsten Fall in die Insolvenz getrieben. Deshalb sollten wir uns im Vorfeld fragen, ob wir es uns erlauben können, SEO als alleinigen Kanal zu nutzen und dabei auch nur auf ein Suchsystem zu setzen.
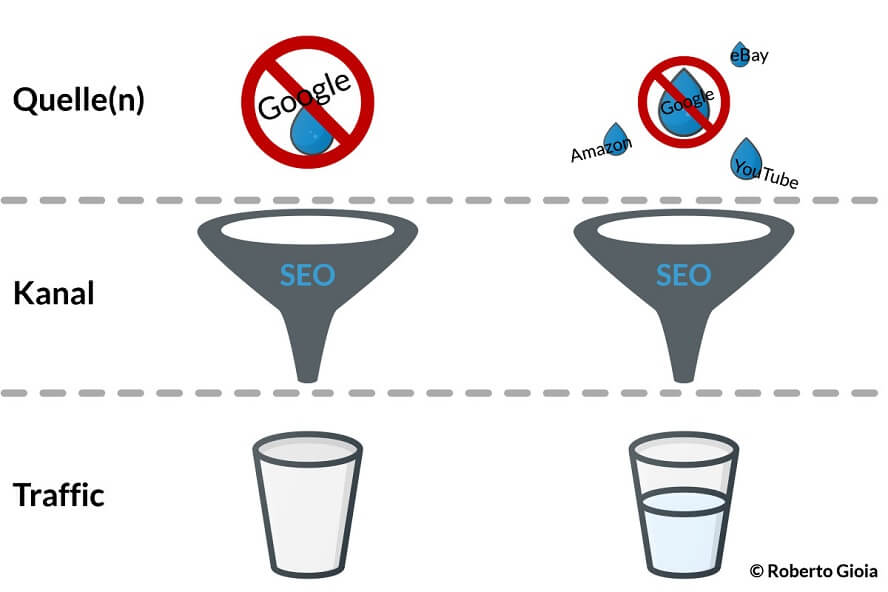
Dies waren nur ein paar Beispiele dafür, was alles schieflaufen kann. Einige Dinge scheinen banal, sind aber trotzdem tausendfach im Internet zu finden… oder auch nicht – sofern jemand weiterhin die JS Browser-Länderweiterleitung von WPML verwendet 😉 .
Aber was soll mir das ganze nun sagen?
Ganz einfach! Du brauchst ein Fehlerpräventionssystem und für den Notfall eine Checkliste mit möglichst vielen Fehlerquellen (inkl. einer Auflistung von Negative SEO Maßnahmen). Die Liste sollte zudem bei jeder neuen Fehler-Erfahrung um dieses Wissen erweitert werden.
Die oben beschriebenen Fälle dienen dazu, zu zeigen, wie vielfältig und unterschiedlich die Fehler sein können. Deshalb sollten wir mehr als nur einen Pfeil “im Köcher“ haben. Fangen wir vorne an:
Briefings
Viele Fehler entstehen beim Kunden, oder einer betreuenden Webagentur. Wenn man hier im Vorfeld aktiv wird und wichtige NoGos richtig kommuniziert, können wir die Fehlerquote signifikant eindämmen. Hier sollten wir nicht alles als selbstverständlich betrachten, sondern auch auf einfachste Dinge eingehen. Doch Achtung, überfordert/überschüttet den Kunden nicht mit Anweisungen – konzentriert euch auf das Wesentliche.
Hier einige Beispiele:
- Vor jedem Update ein Backup machen
- Nach jedem Update den Browser- und Server-Cache leeren und die Seite auf Fehler überprüfen
- Dem SEO bei geplanten Änderungen/oder Problemen auf der Seite, immer früh genug Bescheid geben
- Vor jedem größerem Update den SEO informieren, damit er den vorher nachher Stand ermitteln kann
Monitoring Systeme
Um den vielen technischen und inhaltlichen Fehlern auf die Spur zu kommen, genügt ein Monitoring-System, welches jeden Tag einen Screenshot erstellt, den Source-Code einer Webseite abspeichert und bei Veränderungen eine Nachricht versendet. Das alleine hilft schon den Großteil der Fehler frühzeitig zu identifizieren. Über einen Source-Code Vergleich sehen wir dann, an welchen Stellen sich im Code etwas verändert hat. Häufig geht es (gerade bei großen Seitenbetreibern) mit der Frage einher, wie tausende Seiten überwacht werden sollen? Hier entstehen ja auch zwangsweise täglich viele Änderungen und damit Benachrichtigungen. Die Antwort: Gar nicht! Es werden nur Seiten ins Visier genommen, welche schemenhaft für viele anderen Seiten stehen und Seiten, welche besonders wichtig sind. Beispiele:
- Die Startseite,
- Eine Kategorieseite
- Eine Unterkategorieseite
- Artikel- und/oder Produktseiten
- Wichtige strategische Inhalte
Hierfür gibt es u. A. folgende kostenpflichtige Anbieter:
- Testomato
- KarlsCOREpublic (WHI Tool + Content Monitoring)
- URL-Monitor
Dir oder deinem Kunden steht kein Monitoring-Tool zur Verfügung? Du möchtest aber trotzdem einen Vorher-/Nachhervergleich durchführen? Dann habe ich folgenden Tipp für Dich: Eine einfache und kostenlose Variante, zumindest was den Source-Code anbelangt, bietet Notepad++. Dafür gehen wir wie folgt vor:
Nehmen wir an, wir möchten eine WordPress Seite updaten.
- Dafür speichern wir uns vor dem Update die Frontend Seite (ohne als Admin eingeloggt zu sein) über die Browserfunktion „Seite speichern unter…“ ab.
- Dasselbe machen wir dann auch noch mal nach dem Update. (Immer daran denken, vorher den Cache zu leeren)
- Je nach Bedarf den Code danach mit einem “html beautifier“ verschönern.
- Nun öffnen wir Notepad++ und nutzen hier die Code Vergleichen Funktion unter „Erweiterungen“ >> „Compare“.
- Schon werden einem die Änderungen angezeigt. 🙂
Neben der oben beschriebenen Methode, können wir auch die Daten aus der Search Console (DC, Links, Serverfehler, usw.) nutzen, um mögliche Fehler und sogar Potentiale zu entdecken. Außerdem bietet die Search Console eine API. Workarounds für Excel Liebhaber gibt es auch genügend 😉
Zum Monitoring gehören natürlich auch Links, Inhalte, Server Antwortcodes, Uptime usw.
Sind verschiedene Länderversionen einer Webseite im Einsatz, sollten auch diese überprüft werden.
Checklisten
Wir haben mit der Zeit eine große Checkliste angelegt, welche wir in mehrere Rubriken aufgeteilt haben. Grob sind sie dabei in Präventiv-Maßnahmen und Notfall-Maßnahmen aufgeteilt. Manche haben wir darunter auch noch mal in Fehlerhäufigkeit aufgeteilt und vertaggt. Hier einige Beispiele:
- Relaunch Fallen
- Technische Fehler
- Negativ-SEO (Content-Raub, Link-Klau, schädliche Links (bombing/slow kill), hacking /hijacking, cloaking usw.)
- Probleme, welche nicht direkt erkannt werden können
- Abstrafungen
Achtung: Nicht das Denken ausschalten, wenn wir eine Checkliste benutzen, diese soll uns lediglich unterstützen und schneller voranbringen. Damit haben wir die direkte Überleitung zu unserem letzten Punkt.
Die Zweifachkontrolle
Vier Augen sehen mehr als zwei! Ist man z.B. gerade kurz vor einem Relaunch, oder einer größeren Änderung, empfiehlt es sich, dies nochmal mit einer weiteren Person abzustimmen. Oft gibt es etwas, das wir übersehen haben.
Fazit:
Es gibt viele Arten seine Seite vor Fehlern oder Angriffen zu schützen. Je wichtiger die Seite ist, umso bessere Vorkehrungen sollten getroffen werden. Es empfiehlt sich als Agentur seine Kunden zu briefen und für den Notfall vorgesorgt zu haben. Auch ein Monitoring sollte implementiert werden.
Am besten ist es immer, die Fehler bereits im Vorhinein so gut wie möglich zu minimieren. Und sollte dennoch mal der Fehlerteufel auftauchen (was er definitiv immer irgendwann tut), können wir ruhiger und strukturierter an die Sache herangehen.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





