
Wer verwendet Screaming Frog SEO Spider?
Unternehmen aller Größe verwenden Screaming Frog und SEO Spider, um ihre SEO zu verbessern.
Was ist Screaming Frog SEO Spider?
Screaming Frog ist als Tool für zügiges Crawling bekannt und beliebt. Bei einem Crawl werden sämtliche Links verfolgt. Dabei wird jede einzelne URL aufgerufen und alle vorhandenen Informationen über sie sukzessive gesammelt. So können problemlos einzelne URLs oder auch ganze Domains gecrawlt werden. Diese werden dann Seite für Seite geladen, um alle nötigen Optimierungsmaßnahmen nach Wertung der ausgeworfenen Daten in die Wege leiten zu können.
Der Fokus dieses SEO-Tools liegt bei OnPage-Analysen. Die Daten lassen sich exportieren und anschaulich aufbereiten. Der Screaming Frog SEO Spider informiert über defekte Links oder die Linkstruktur selbst. Metadaten können extrahiert werden.
Attraktive Zusatzfunktionen mit „Custom Extraction“ und „ Custom Search“ bieten weitere Analysemöglichkeiten, um in die Tiefe gehen zu können.
Das Tool ist in drei Modi unterteilt:
- Crawl-Modus: Der Frog SEO Spider lädt eine URL und folgt von da aus allen vorhandenen Links. Wer richtig große Seiten crawlen möchte, benötigt dafür ein spezialisiertes Tool.
- List-Modus: Hier werden bestimmte festgelegte Seiten dem Frog SEO Spider zum Crawlen
Übergeben. Es werden dann genau nur diese Seiten überprüft - SERP-Modus: Dieser Modus überprüft Seitentitel und Meta-Descriptions auf ihre korrekte Länge
Top:
Die Geschwindigkeit des Crawlers lässt sich mit sogenannten „Speed-Optionen“ steuern. Nice to have.
Manko:
Das Programm ist eher was für Kenner mit SEO-Wissen. Auf Hilfe-Features wird weitestgehend verzichtet. Das Tool muss extra installiert werden. Zum Teil ist die Optik veraltet. Ergebnisse werden ausschließlich in Tabellenform
angezeigt, deswegen sind SEO-Kenntnisse erforderlich.
Screaming Frog SEO Spider Bewertungen / Erfahrungen
Diese Screaming Frog SEO Spider-Bewertungen werden automatisch aus 27 eingereichten Nutzer-Erfahrungen ermittelt.
Screaming Frog SEO Spider Rezensionen
„Screaming Frog ist ein technischer SEO-Scanner, der den tatsächlichen Zustand einer Website transparent und messbar macht.“
Christian Krenn
Entwickler
Screaming Frog ist ein echtes Power-Tool für technische SEO-Analysen. Es crawlt Websites extrem schnell und liefert sehr saubere, detaillierte Daten zu allem, was technisch relevant ist, von Statuscodes über Weiterleitungen bis hin zu Meta-Daten und interner Verlinkung. Besonders bei größeren Websites spielt das Tool seine Stärke aus, da es volle Kontrolle über die Daten bietet und umfangreiche Filter- und Exportmöglichkeiten liefert.
Nachteile von Screaming Frog SEO SpiderDer größte Nachteil ist, dass Screaming Frog kein klassisches Plug-and-Play-Tool ist. Die Oberfläche wirkt zunächst eher nüchtern und kann vor allem für Einsteiger schnell überfordernd sein. Zudem ist die kostenlose Version stark limitiert, sodass bei professionellen Projekten kaum ein Weg an der kostenpflichtigen Variante vorbeiführt.
Beste Funktionen von Screaming Frog SEO SpiderAm häufigsten kommt der klassische Crawl zum Einsatz.
Allgemeines Fazit zu Screaming Frog SEO SpiderScreaming Frog ist kein Einsteiger-Tool, sondern ein klarer Profi-Standard für alle, die technische SEO auf hohem Niveau betreiben. In professionellen SEO-Setups gehört es zur absoluten Grundausstattung.
„Der beste Crawler auf dem Markt und für SEOs im Grunde unverzichtbar.“
Philipp Schwarze
SEO, SEA, Redaktion
Praktischer Crawler, der dabei hilft, Websites auf Herz und Nieren zu prüfen, um Fehler und Optimierungspotenzial zu finden. Die Daten liegen in Tabellenform vor und lassen sich nach zahlreichen Kriterien filtern, sortieren und untersuchen. Zudem besteht die Möglichkeit, alles als .csv zu exportieren und mit Programmen wie Excel weiter zu bearbeiten und an die eigenen Bedürfnisse anzupassen.
Nachteile von Screaming Frog SEO SpiderScreamingFrog ist sperrig. Die ersten Schritte gehen noch gut von der Hand. Aber das Tool schaufelt so viele Daten zusammen, dass gerade bei großen Websites schnell die Übersicht verloren geht. Dann gilt es, Filter zu nutzen, die teils etwas schwierig zu finden sind. Und ScreamingFrog legt wenig bis gar keinen Wert auf eine ansprechende optische Präsentation. Zudem ist die Dichte an Fachbegriffen hoch und die Möglichkeiten, Daten auszulesen, sind immens. Fachwissen ist nötig und eine Einarbeitung in das Tool ebenfalls. Tutorials, Videos und Co gibt es allerdings genug.
Beste Funktionen von Screaming Frog SEO SpiderRegelmäßiges Crawling, um Fehler auf Websites zu finden.
Allgemeines Fazit zu Screaming Frog SEO SpiderWer SEO ernsthaft betreibt, kommt am Frosch nicht vorbei. Es gibt sicher ähnliche Tools, die auch viel richtig machen, aber in Sachen Umfang und Möglichkeiten der Weiterverarbeitung macht ScreamingFrog keiner was vor. Allerdings erfordert die Nutzung auch einiges an Einarbeitungszeit.
„Der Schweizer Taschenmesser-Crawler für technische SEOs.“
Bernd Verhey
SEO Manager
Isoled GmbH
Extrem leistungsstarker SEO-Crawler mit hoher Analyse-Tiefe
Sehr flexibel und anpassbar (Custom Extraction, API-Anbindungen etc.)
Schnelle Crawls, auch bei großen Websites
Gute Exportfunktionen und Datenvisualisierungsmöglichkeiten
Für Einsteiger kann der Funktionsumfang anfangs überwältigend sein
Beste Funktionen von Screaming Frog SEO SpiderSEO-Crawl mit detaillierter Analyse von Meta-Daten, Canonicals und Statuscodes
Integration mit der Google Search Console und GA für erweiterte Insights
Custom Extraction für spezifische Onpage-Faktoren
Screaming Frog ist ein absolutes Muss für professionelle SEOs – leistungsfähig, flexibel und verlässlich. Wer sich mit der Oberfläche zurechtfindet, bekommt eines der besten Tools auf dem Markt.
„Einfaches SEO in “Checklisten” Format“
Anita Tiefau
Leiterin digitale Transformation
Einfach, detailliert, umfassend – das sind die Stichworte, die mir bei Screaming Frog als erstes einfallen. Für jeden, der die Anfänger-Schuhe im SEO Bereich hinter sich gelassen hat und etwas mehr in die Tiefe gehen möchte, ist Screaming Frog zur Onpage-Analyse ein gelungenes Tool.
Technische Fehler werden effizient und schnell erkannt, alle relevanten Daten sind vorhanden und man kann alles auch noch exportieren, falls notwendig.
Ohne Grundkenntnisse im SEO Bereich ist es schwer, das volle Potenzial des Tools komplett auszuschöpfen.
Beste Funktionen von Screaming Frog SEO SpiderIch prüfe die Bildgrößen und Dateiformate und optimiere diese ggf.
Fehlende Metadaten oder defekte Links erkennen und korrigieren/beheben.
Man muss nur die richtige Fragestellung haben, dann findet man in Screaming Frog die passende Antwort. Nach und nach kann man sich so mit einzelnen Optimierungsschritten durch die eigene Website arbeiten.
Es bietet viele Möglichkeiten, das korrekte Funktionieren einer Webseite zu überprüfen, z. B. Links (intern und extern), Titel usw. Selbst mit Grundkenntnissen sind die meisten Grundfunktionen intuitiv.
Nachteile von Screaming Frog SEO Spiderviele fortgeschrittene Funktionen, die ohne einen Workshop schwer zu verstehen sind. Keine gemeinsame Lizenz als Unternehmen.
Beste Funktionen von Screaming Frog SEO SpiderPrüfung Antwort Codes, Seitentitle, Meta Descriptions, h1, h2.
Allgemeines Fazit zu Screaming Frog SEO SpiderEs ist ein Must-Have für Website Relaunch oder ähnliches, aber könnte besser sein mit eine gute Einführung in das Tool
„Screaming Frog SEO Spider ist ein unverzichtbares Tool für jeden, der technische SEO ernst nimmt und Webseiten effizient optimieren möchte.“
Yannick Höflacher
Inhaber
Ein großer Vorteil von Screaming Frog SEO Spider ist die umfassende Analyse von Webseiten, die das Tool in kürzester Zeit durchführen kann. Es ermöglicht eine detaillierte Untersuchung technischer SEO-Aspekte wie defekte Links, fehlende Meta-Beschreibungen, doppelte Inhalte und Weiterleitungen. Besonders nützlich ist die Möglichkeit, große Websites systematisch zu crawlen und strukturiert auszuwerten. Zudem bietet das Tool eine einfache Exportfunktion, mit der die Daten in Excel oder Google Sheets weiterverarbeitet werden können.
Nachteile von Screaming Frog SEO SpiderEin Nachteil von Screaming Frog SEO Spider ist die etwas komplexe Benutzeroberfläche, die für Einsteiger zunächst überwältigend wirken kann. Das Tool erfordert eine gewisse Einarbeitungszeit, um alle Funktionen optimal nutzen zu können. Außerdem ist die kostenlose Version auf 500 URLs begrenzt, was für größere Websites schnell zum Problem wird. Die Vollversion mit unbegrenztem Crawling ist kostenpflichtig, was für kleine Unternehmen oder Einzelpersonen eine Hürde darstellen kann.
Beste Funktionen von Screaming Frog SEO SpiderAm liebsten nutze ich die Funktion zur Erkennung von 404-Fehlern und Weiterleitungen, da sie mir hilft, technische SEO-Probleme schnell zu identifizieren und zu beheben. Besonders praktisch finde ich auch die Analyse von Title-Tags und Meta-Beschreibungen, um Optimierungspotenziale für bessere Rankings in Suchmaschinen zu entdecken. Die Möglichkeit, XML-Sitemaps zu generieren, ist ebenfalls sehr hilfreich.
Allgemeines Fazit zu Screaming Frog SEO SpiderScreaming Frog SEO Spider ist ein äußerst leistungsstarkes und zuverlässiges Tool für die technische SEO-Analyse. Es bietet eine Vielzahl an Funktionen, die Website-Betreibern und SEO-Experten dabei helfen, Fehler zu identifizieren und Optimierungspotenziale auszuschöpfen. Obwohl die Benutzeroberfläche für Einsteiger etwas komplex wirken kann, lohnt sich die Einarbeitung in das Tool, da es wertvolle Einblicke in die Webseitenstruktur liefert.
„Insgesamt ist Screaming Frog SEO Spider ein unverzichtbares Werkzeug für SEO-Profis und Website-Betreiber, die eine tiefgehende technische Analyse ihrer Website durchführen möchten.“
Franziska Kachel
Marketing Manager
• Umfassende Analysefunktionen: Screaming Frog bietet detaillierte Einblicke in die Website-Struktur und hilft, technische SEO-Probleme effektiv zu identifizieren.
• Benutzerdefiniertes Crawling: Nutzer können genau definieren, welche Seiten oder Bereiche der Website gecrawlt werden sollen, was eine gezielte Analyse ermöglicht.
• Regelmäßige Updates: Das Tool wird kontinuierlich weiterentwickelt und mit neuen Funktionen ausgestattet, um den sich ändernden Anforderungen im SEO-Bereich gerecht zu werden.
• Einarbeitungszeit für Anfänger: Aufgrund der Vielzahl an Funktionen kann das Tool für SEO-Neulinge anfangs überwältigend sein und erfordert eine gewisse Lernkurve.
• Kosten für erweiterte Funktionen: Während die kostenlose Version bis zu 500 URLs crawlen kann, sind für größere Projekte und erweiterte Funktionen kostenpflichtige Lizenzen erforderlich.
Regelmäßige On-Page-Analyse um defekte Links, doppelte Inhalte und fehlende Metadaten zu identifizieren damit letztlich die Website-Performance verbessert wird.
Allgemeines Fazit zu Screaming Frog SEO Spider• Website-Crawling und -Analyse: Das Tool durchsucht Websites effizient und liefert in Echtzeit Analysen zu defekten Links, Serverfehlern, Weiterleitungen und Sicherheitslücken. Es bietet tiefe Einblicke in Seitentitel und Metadaten, um Probleme wie doppelte Inhalte oder schlecht optimierte Tags zu erkennen.
• SEO-Auditing und -Optimierung: Screaming Frog prüft Weiterleitungen, robots.txt-Dateien und Meta-Robots-Direktiven. Es identifiziert komplexe Weiterleitungsketten und -schleifen, die die Sichtbarkeit in Suchmaschinen beeinträchtigen können. Zudem generiert es XML-Sitemaps und bietet Funktionen zur benutzerdefinierten Quellcode-Suche.
• Integration mit Drittanbieter-Tools: Das Tool verfügt über API-Schnittstellen zu Google Analytics, Google Search Console und PageSpeed Insights, was die Erstellung detaillierter Crawls ermöglicht.
„Sehr hilfreiches Tool für kleines Geld, welches selbsterklärend ist und keine zeit- und geldintensive Seminare erfordert.“
Panagiotis
Sarafoudis
GF
– Einfach und simple aufgebaut.
– Gut strukturiert. Ohne viel Schnick-Schnack
– Super schnelle Nutzung. Man sieht genau die Details, welche man auch wirklich braucht
– Mehrere H2 und H3 sollten direkt im Menü auswählbar sein, ohne die komplizierte “Syntax” selbst aufzubauen und speichern zu müssen.
Beste Funktionen von Screaming Frog SEO Spider– H1 – Hx, alle!
– Fehlererkennung bzw. Fehlerhinweise
Super! Das ist ein Muss. Ein Support habe ich bisher nie gebraucht.
„Für SEO Experten ist Screaming Frog ein äußerst wertvolles Tool für die schnelle Analyse und Fehleraufdeckung von Websites.“
Niklas von Nieding
Online-Marketing Manager
Screaming Frog ist ein erstmal kostenloses Tool um Webseiten zu analysieren und aus meiner Sicht ein Must-Have.
Man kann damit super effizient 404 Fehler oder 301 Weiterleitungen aufdecken, Meta-Titel und Meta-Descriptions Analysieren oder interne Verlinkungen prüfen.
Die Limitierung des Crawlings auf 500 Einträge in der kostenlosen Version wirkt schon teilweise etwas wenig, da auch Bild-URLs oder CSS Dateien gecrawlt werden können und als Eintrag zählen. Das kann in der kostenpflichtigen Version deaktiviert werden.
Außerdem ist das Userinterface veraltet und nicht intuitiv, aber man findet sich irgendwie zurecht
Ich nutze Screaming Frog gerne, um schnell die Statuscodes zu überprüfen und eventuelle 404-Fehler, Weiterleitungen oder defekte Links zu korrigieren.
Allgemeines Fazit zu Screaming Frog SEO SpiderScreaming Frog ist für mich ein Must-Have und erleichtert die Überprüfung vieler SEO relevanter Faktoren ungemein!
Screaming Frog ist eines der mächtigsten SEO-Tools, die es auf dem aktuellen Markt gibt. Mithilfe von Screaming Frog kann man alles über seine eigene Webseite herausfinden, was insbesondere aus technischer Sicht wichtig zu wissen ist. Zu den größten Stärken gehört meiner Meinung nach die API-Schnittstellen zu Google Analytics, Search Console aber auch zum Page Speed Lighthouse, wodurch unglaublich detaillierte Crawls erstellt werden können.
Nachteile von Screaming Frog SEO SpiderDie Usability des Tools ist nicht immer einleuchtend, aber an der Tatsache wird seit Jahren vom Team gearbeitet und gefeilt. Screaming Frog ist kein Tool für Einsteiger, alleine die Konfiguration der Einstellungen für ein gutes Crawl Ergebnis können für einiges Haareraufen sorgen.
Beste Funktionen von Screaming Frog SEO SpiderNeben den Bulk Exporten nutze ich gerade bei kleinen Seiten enorm gerne die PageSpeed-API. Weiterhin sehr hilfreich ist es, die gecrawlten Daten zu clustern. Seitenstruktur und typische SEO-Issues sind ebenfalls schnell identifiziert.
Allgemeines Fazit zu Screaming Frog SEO SpiderEines der meiner Meinung nach wichtigsten Tools im SEO-Bereich und ein Tool, welches jeder SEO-Manager in seinem Toolbelt besitzen sollte. Selbst mit den Standard Konfigurationen erhält man bereits alle Daten, die man benötigt für jegliche Optimierungen.
„Der Frog ist das beste Crawlingtool, das es gibt.“
M. H.
Senior Online Marketing Manager
itemis ag
Das Tool wird ständig erweitert und kann alles Mögliche crawlen (auch über APIs Verknüpfung mit Search console, Analytics etc.). Der Output ist umfangreich und einfach per CSV downloadbar.
Nachteile von Screaming Frog SEO SpiderIch sehe keine.
Beste Funktionen von Screaming Frog SEO SpiderIch crawle oft nach 3xx und 4xx Fehlern. Nutze es aber auch um Seiten zu identifizieren, die noch keine “schönen” Snippets und Hx haben.
Allgemeines Fazit zu Screaming Frog SEO SpiderWenn man Auswertungen nicht bunt dargestellt braucht, gibt es kein besseres.
„Jeder, der etwas mit SEO zutun hat, sollte sich dieses Tool anschaffen!“
P. E.
Online Marketing Manager
- hilft jedem SEO weiter
- es wird stets an Erweiterungen gearbeitet
- Top Preis-Leistung
- enorm umfangreich
erklärungsbedürftig
Beste Funktionen von Screaming Frog SEO Spider- Status-Codes checken
- Inlinks!!!
Hammer-Tool
„Investiere die Zeit den Umgang mit diesem Tool zu lernen – Es wird sich x-fach für Dich auszahlen.“
Alexander Buding
Performance Marketing Manager
Babor
Es kann alles was man für ein technisches SEO-Audit benötigt – und noch vieles darüber hinaus. Updates und viele neue Features gibt es regelmäßig, so dass es immer zeitgemäß genutzt werden kann.
Nachteile von Screaming Frog SEO SpiderMan braucht einige Zeit und ein gewisses Level an Know-how, um es sinnvoll nutzen zu können – nichts für Anfänger oder “Adhoc-User”
Manchmal funktioniert die APIs zu Google Analytics, GSC, Lighthouse, etc. nicht.
Xpath-Extractor, Broken-Link Analysis, generell den Onpage-Crawl zur Identifizierung fehlender H1, h2, metas, etc.
Allgemeines Fazit zu Screaming Frog SEO SpiderMega – Für SEOs unerlässlich. Preis-Leistung ist kaum schlagbar.
„Der Frosch bietet einen schnellen und guten Überblick über den aktuellen Website-Zustand.“
Suzanne Dilli
SEO Consultant
Die kostenlose Variante ist ideal zum Testen geeignet und reicht bei kleinen Projekten aus. Die wichtigsten Funktionen sind auch bei dieser Version nutzbar.
Das Crawling von Webseiten verläuft auch bei größeren Seiten flüssig und schnell. Hier wurde die Performance in den letzten Jahren gut weiterentwickelt.
Sehr umfangreiche Funktionen.
Sehr umfangreiche Funktionen. Eine Intuitive Nutzung ist für die Grundlagen gegeben, sobald es spezifischer wird, muss man sich reinfuchsen. Sobald die Einstellungen passen, läuft es aber gut, also eigentlich kein wirklich negativer Punkt.
Beste Funktionen von Screaming Frog SEO SpiderSimples Crawling zur Statuskontrolle der wichtigsten technischen Werte (Statuscodes, Indexierbarkeit, Redirects, Metadaten, etc.)
check der internen Verlinkungen und des allgemeinen Websitezustands.
Der Screamingfrog bietet umfangreiche Funktionen für den SEO-Alltag. Er ist eigentlich ständig in Benutzung und eine mehr als nur eine Ergänzung der üblichen Tools.
*Must have*
„Der schnellste und gleichzeitig umfangreiche Crawler für kleines Geld“
Helen Schrader
Online Marketing Manager
Sehr schneller Crawler, der stetig neue Features entwickelt und hinzufügt. Vor allem die recht neu hinzugefügte Datatstudio-Verknüpfung sowie die schon etwas länger bestehende Vergleichsmöglichkeit von Crawls macht das Tool sehr mächtig.
Ansonsten ist ScreamingFrog ein wenig wie das Excel unter den SEO-Tools. Bei jedem Tweet, Update oder Artikel, den ich über das Tool lese, finde ich etwas aufregendes Neues.
Auf den ersten Blick sehr unübersichtlich und leider funktioniert es nur, wenn der Rechner läuft, was gerade terminierte Crawls stellenweise mal in Bedrängnis bringt.
Beste Funktionen von Screaming Frog SEO SpiderDie Response Code Hinweise sowie den hreflang und Canonical Checker
Allgemeines Fazit zu Screaming Frog SEO SpiderWahnsinnig mächtiges Tool, in das man sich etwas hereinfuchsen muss, was aber dank der hervorragenden Guides und Beschreibungen auf der Seite von SF auch kein Problem ist. Für Experten ein gerne genutztes Tool.
„Der Screaming Frog ist das Schweizer Taschenmesser für SEOs.“
Klaus Wockenfoth
Online Marketing Manager
Der Screaming Frog liefert sämtliche Daten, die ein SEO für seine tägliche Arbeit benötigt. Er eignet sich, um eine komplette Website in allen Details zu prüfen oder auch nur “mal eben” einen Schnellcheck von bestimmten Seiten zu machen. Die Konfigurations- und Analysemöglichkeiten des Tools lassen kaum einen Wunsch offen. Und falls doch mal einer besteht, kommt die entsprechende Funktion meistens mit einem der nächsten Releases.
Nachteile von Screaming Frog SEO SpiderDie Lernkurve kann extrem steil sein. Gerade weil das Tool sehr viele Möglichkeiten bietet, sollte man sich unbedingt die Zeit nehmen und sich ordentlich in das Werkzeug einarbeiten. Nur so kann man das volle Potential nutzen.
Beste Funktionen von Screaming Frog SEO SpiderEs gibt kaum eine Funktion, die ich nicht gerne nutze. Am liebsten verwende ich jedoch die Visualisierungen (Crawl bzw. Directory Tree etc).
Allgemeines Fazit zu Screaming Frog SEO SpiderDas Tool ist jedem zu empfehlen, der sich mit SEO beschäftigt. Es gibt kaum eine andere Lösung, die für den Preis eine derartige Leistung bietet.
Es gibt das Tool in einer Freeversion, mit der Websites mit maximal 500 Unterseiten gecrawlt werden können und somit eine super Lösung für kleine Projekte ist. Selbst die kostenpflichtige Version ist im Vergleich zu anderen Crawling Tools eine sehr günstige Alternative. Im Preisleistungsvergleich ein unschlagbares Tool, um Onpage-Analysen zu erstellen.
Neben den umfangreichen Daten, die das Tool bei einem Crawl erhebt, können diese auch durch weitere Informationen von Analytics und der Search Console ergänzt werden. Ein weiterer Vorteil des Tool ist es, dass die erhobenen Daten mit dem Bulk-Export in Excel oder Google Sheets überführt werden können und dort mit ein wenig “Tabellenmagie” schnelle Reports erzeugt werden können. Durch die Custom Extraction können punktuell Daten erhoben werden, was sich bei der Fehlersuche als großen Pluspunkt bemerkbar macht. Da der ScreamingFrog verschiedene Modi oder User Agents im Crawling abbilden kann, ist er sehr vielseitig einsetzbar z.B. bei der Vorbereitung eines Relaunches oder in der Qualitätssicherung.
Da der ScreamingFrog keine eigenen Analyse Reports erstellt, sollte der Nutzer schon wissen, wo er hinschaut, um Fehleranalysen zu betreiben. Vor- und Nachteil des Tools ist die lokale Installation auf dem Rechner, welcher schnell bei großen Seiten Performanceprobleme bekommt oder Tage durchlaufen muss, um den Crawl fertigzustellen. Wenn sehr viel Wert auf Design innerhalb einer Bedienoberfläche gelegt wird, dann muss man hier auch Abstriche machen.
Beste Funktionen von Screaming Frog SEO SpiderDie beste Funktion ist wohl die Vielseitigkeit des Tools – ob individuelle Listen oder bestimmte Inhaltselemente untersucht werden sollen oder um schnell die falschen internen Verlinkungen zu finden.
Allgemeines Fazit zu Screaming Frog SEO SpiderWer schnell einen Überblick bei der Onpage-Optimierung einer Webseite benötigt und später einzelne Fehleranalysen durchführen möchte, sollte den ScreamingFrog ausprobieren. Das Tool ist ein Must-have!
„The one and only, wenn es um Crawls und ausführliche OnPage-Analysen geht!“
Aleks Bujko
SEO-Manager
Durch die ständige Weiterentwicklung bietet das Tool eine riesige Anzahl an Funktionen und Einstellungsmöglichkeiten. An dieser Stelle ist es ebenfalls beachtlich, dass das Entwicklungsteam den User-Guide und die FAQs auf der Seite stets aktuell halten.
Einen weiteren Vorteil stellt die Anbindung der externen Daten (aus GSC, Analytics, etc.) dar, mit denen die Crawls bereichert werden können.
Besonderes hilfreiche Funktionen sind die Sitemap-Erstellung und die Möglichkeiten der Visualisierung. Zudem können mit dem JS-Rendering die Seiten so gecrawlt werden, wie der Googlebot sie tatsächlich sieht.
Gelegentlich merkt man, dass das JS-Rendering doch nicht so gut funktioniert. Der größte Nachteil des Tools ist jedoch der große Hunger für CPU-Ressourcen – große Crawls können sehr lange dauern und den Rechner überfordern.
Mittlerweile ist die Benutzeroberfläche aufgrund der hohen Anzahl an Funktionen nicht mehr wirklich intuitiv. Auch das Einstellen der Custom Extraction kann problematisch sein.
List-Mode-Crawls, Sitemap-Erstellung, Bulk-Exports, JS-Rendering beim Crawlen.
Allgemeines Fazit zu Screaming Frog SEO SpiderAuch wenn man am Anfang recht lange braucht, um bei allen Funktionalitäten durchzublicken, ist das Tool ein echter Alleskönner!
Die mit den Boardmitteln gecrawlten Metriken werden durch Custom Search & Extraction sowie Zugriff auf die wichtigsten API ergänzt und lassen keine Wünsche mehr übrig.
Durch die Scheduling-Funktion und die Möglichkeit, Exporte in Google Drive zu speichern, lassen sich komplexe und 100%-automatisierte Reporte mit einem geringen Aufwand erstellen.
Es gibt leider kein öffentliches API. Auch ist es schade, dass Proxy-Rotation sich nur über einen Umweg machen lässt.
Beste Funktionen von Screaming Frog SEO SpiderCustom Extraction – mit dieser Funktion kann ich alles aus einer Seite auslesen, anstatt ein Riesen-Overhead an per default gecrawlten Daten zu produzieren. Meine Basis-Konfiguration ist leer – für jeden Crawl sammle ich nur die Daten, die ich tatsächlich brauche.
Allgemeines Fazit zu Screaming Frog SEO SpiderSehr gelungenes Tool. Und, seit der Optimierung des Speichermechanismus, ist das Tool auch für richtig große Seiten geeignet.
„Gehört zum Standard-Setup von jedem, der SEO schreiben kann oder es lernen möchte.“
Maximilian Bloch
SEO-Consultant
- Integrationen sind Gold wert, z.B. GSC-/Analytics/PSI-Connection
- JS-Rendering-Fähigkeit
- Beim Crawl wird inzwischen (seit einigen Jahren bereits?) die Festplatte zum Zwischenspeichern verwendet, früher musste das noch alles in den RAM.
- Ressourcenhungrig
- Java-typische Trägheit
Den Crawl mit aktiviertem JS-Rendering, Custom Search, List-Mode.
Allgemeines Fazit zu Screaming Frog SEO SpiderDer wohl beste SEO-Crawler den ein Client je ausführen durfte.
„… ein SEO Projekt ohne Screaming Frog gibt es nicht 🙂 Das Tool ist ein wertvoller Begleiter.“
Marco Mayer
Geschäftsführer
Das Tool ist perfekt geeignet zum Crawlen von kleinen und sehr großen Webseiten. In den Grundeinstellungen tut das Tool genau das was es soll und ist in der Freeware für kleine Firmen bis 500 Unterseiten bereits gut zu benutzen. In der günstigen Bezahlversion entfaltet es dann seinen vollen Funktionsumfang der im Detail sehr mächtig ist und aus professioneller Sicht fast keine Wünsche offen lässt. Es gibt viele Filter- und Anpassungsmöglichkeiten und natürlich auch einen Export, sobald der Crawl erfolgreich beendet wurde.
Nachteile von Screaming Frog SEO SpiderBei sehr großen Seiten muss man viel Geduld mitbringen. (was aber auch der Seitengröße geschuldet ist und nur bedingt dem Tool) Die Oberfläche wirkt sehr technisch aufgeräumt und ist damit weniger etwas für Menschen die grafisch ansprechende Software mögen. Die Einarbeitung in die tiefen des Programms und all seiner Möglichkeiten nimmt Zeit in Anspruch.
Beste Funktionen von Screaming Frog SEO SpiderUm einen guten Überblick über die Seitenstruktur zu bekommen, die inhaltlichen Themen und generell einen Export “aller” Informationen zur Seite zu haben, ist dieses Tool sehr gut geeignet.
Allgemeines Fazit zu Screaming Frog SEO SpiderFür SEO’s meiner Meinung nach eines der Must Have Tools, wenn es darum geht den IST-Zustand der Seite zu ermitteln und natürlich auch für Zwischenkontrollen bei umfangreichen Projekten.
„Für kleine Webseiten und nicht völlig im Chaos versinkende Shops etc. sogar in der limitieren Free-Version gut zu gebrauchen.“
Miladin Mechenbier
Zugpferd
Ganz klar: In einer limitierten Version ist das Tool kostenlos zu haben – das ist erstmal perfekt.
Mit 500-Seiten-Crawls kann man – wenn bei großen Seiten die interne Link-Struktur kein völliges Chaos ist sowie natürlich bei kleinen Seiten – durchaus schon sehr viele Probleme in kürzester Zeit aufdecken.
Mit dem Support hatte ich bisher noch keinen Kontakt, weil ich schlicht immer mit dem Tool zurecht kam.
Weiterempfohlen habe ich es im Laufe der Jahre schon dutzende Male – und es kamen mir noch keine Beschwerden zu Ohren.
Nachteile von Screaming Frog SEO SpiderAus der eigenen Erfahrung kann ich keine Nachteile nennen.
Auf Konferenzen und in Konzernen habe ich ein paarmal gehört, dass der “Screaming Frog” für gewisse komplexe Anforderungen nicht geeignet sein soll. Wenn Du aber davon betroffen sein solltest, musst Du eh aufhören, diese Bewertung zu lesen – fang’ an zu testen und zu vergleichen. 😉
Beste Funktionen von Screaming Frog SEO SpiderAlleine schon mit den Details inkl. der “Inlinks” und “Outlinks” finden die meisten Webseitenbetreiber einige Probleme, die es zu lösen gilt.
Mit diesen Basisfunktionen fängt es meist an.
Allgemeines Fazit zu Screaming Frog SEO SpiderNix zu meckern – also einfach testen!
Viele Konfigurationsmöglichkeiten
Javascript-Crawling
Enorm gutes Preis-Leistungs Verhältnis
Verschiedene Vorkonfigurierte User Agents
Praktische API Anbindungen
Läuft lokal (ist auch ein Vorteil, lastet aber den Rechner teils ordentlich aus)
Nicht komplett intuitiv bedienbar (Bedarf ein gewisses Level)
Vorkonfigurierte User Agents, Java Script Crawling, List Mode (Redirect Checkup), Sitemap Testing
Allgemeines Fazit zu Screaming Frog SEO SpiderDer Screaming Frog als Spider bietet unfassbar viele Konfigurationsmöglichkeiten und erleichtert das Reproduzieren und das Erfassen von Websites in Struktur und Technik ungemein. Dabei ist es sehr gute geeignet um Livegangbetreuungen zu machen oder sich schnell einen ersten Überblick über Websites zu verschaffen.
„Der Screaming Frog bietet auf einfache Art und Weise, aber präzise einen Status quo der Webseite und deckt unweigerlich Fehler auf.“
Markus Fritzsche
Online Marketing Berater
Das Tool liefert in der Grundeinstellung schon eine sehr große Menge an Daten. Dank weiteren eingestellten Extractions und Custom Filtern, können so noch mehr Daen über den Screaming Frog erfasst werden. Der Screaming Frog bietet ein Scheduling an, sodass automatisiert in einem bestimmten Abstand, täglich, wöchentlich, etc. die URL gecrawlt wird und sich auch die entsprechenden Exports ablegen lassen. Wenn alle möglichen Exporte ausgespielt werden, bekommt man 253 Dateien als Excel geliefert.
Der Screaming Frog wird stetig weiterentwickelt, sodass es relativ oft neue Features gibt. Acuh eine Anbindung von Tools wie Google Analytics, GSC, o. ä. ist möglich.
Es handelt sich um ein rein Datengetriebenes Tool. Es gibt keine grafische Oberfläche, in der die Daten zusammengefasst aufbereitet werden.
Beste Funktionen von Screaming Frog SEO Spider– Das Scheduling zum automatisierten Crawl der Seite.
– Den gezielten Export von bestimmten Listen
– Die Crawl Analye
Der Screaming Frog gehört unweigerlich zu den Tools, die im Alltag eines SEO genutzt werden sollten. Man hat hier quasi das schweizer Taschenmesser zur Analyse von Webseiten. Ich kann den Screaming Frog uneingeschränkt weiterempfehlen.
„Der Screaming Frog ist ein Crawling Tool, mit dem man Onpage-Analysen von Websites durchführen kann.“
Mareike Doll
Team Lead SEO
Der Screaming Frog ist ein Crawling Tool, das unglaublich viele Funktionen enthält, die bei der Onpage-Analyse einer Website helfen. Im Vergleich zu anderen Tools ist er außerdem sehr günstig. Ich glaube, es gibt kaum ein anderes Tool, mit dem man so einfach und schnell Status Codes, Meta-Daten, interne Verlinkung und viele andere Aspekte einer Website prüfen kann. Man braucht zwar ein gewisses Verständnis für Websites und Websitestrukturen, um mit dem Tool umgehen zu können und aus den Ergebnissen die richtigen Schlüsse ziehen zu können, aber dann ist es auch für Anfänger möglich mit Hilfe der gewonnenen Informationen Websites zu optimieren. Trotzdem bietet der Screaming Frog auch viele Funktionen an, die für tiefergehende Analyse praktisch sind.
Die Crawls lassen sich als Excel-Datei exportieren, so dass man mit den erfassten Daten direkt weiterarbeiten kann. Sehr praktisch sind die unterschiedlichen Modi, mit denen man sowohl eine ganze Website aber auch eine Liste oder eine Sitemap abcrawlen kann. Mit den Bulk-Exporten lassen sich die erfassten Daten auch noch unter verschiedenen Gesichtspunkten exportieren.
Ein Nachteil des Tools besteht vielleicht darin, dass es keine Empfehlungen zu den erfassten Daten bietet. Gerade für Nutzer, denen der fachliche Background fehlt, ist es so etwas schwierig einschätzen zu können, was die gesammelten Informationen aussagen und wie man mit diesen weiterarbeiten kann. Auf der anderen Seite muss man aber auch die Einschätzungen, die andere Tools in diese Richtung geben, immer kritisch hinterfragen. Mir ist es schon oft passiert, dass Fehler als kritisch ausgezeichnet wurden, die aber in keiner Weise die Performance der Website beeinträchtigt haben. Oder dass schwerwiegende Fehler lediglich als Hinweis ausgezeichnet waren. Auch die Konfiguration des Tools ist für Laien unter Umständen nicht ganz einfach zu durchschauen.
Bei sehr großen Websites stößt der Crawler zudem schon mal an seine Grenzen. Dies ist aber auch von der genutzten Hardware abhängig, auf der das Tool läuft. Cloud-basierte Tools haben hier einen Vorteil.
Der Screaming Frog hat so unglaublich viele Funktionen, dass es wirklich schwer ist, ein paar Lieblingsfunktionen zu nennen. Sehr praktisch ist auf jeden Fall, dass man sich anzeigen lassen kann, ob URLs indexierbar sind.
Allgemeines Fazit zu Screaming Frog SEO SpiderInsgesamt ist der Screaming Frog ein gutes Tool für Onpage-Analysen, das zu einem wirklich günstigen Preis erhältlich ist. Ein wenig Fachwissen sollte man schon mitbringen, aber wenn man sich einmal mit dem Tool auseinandergesetzt hat und seine Funktionen verstanden hat, kann man damit sehr gut arbeiten.
„Top Tool für einen umfangreichen Onsite-Check, das benutzerfreundlich und leicht zu lernen ist – auch in seiner kostenlosen Version oft (je nach Projektumfang) ausreichend.“
Daniel Bruckhaus
Geschäftsführer
Screaming Frog ist ein Website-Crawler-Tool, welches sowohl als kostenlose als auch als bezahlbare Vollversion zur Verfügung steht. Screaming Frog wird nicht im Browser gestartet, sondern als Programm heruntergeladen und ist sehr einfach zu bedienen – selbst für Einsteiger. Mit diesem Tool kann eine ausführliche und umfangreiche Onsite-Analyse unter der Berücksichtigung von vielen Aspekten durchgeführt werden: Überprüfung von URL Strukturen, robots.txt, Meta Daten, Attributen, Duplicate Content, Broken Links, Server- und Browserfehlern und vieles mehr. Dabei startet die Analyse durch die Eingabe einer URL und der Spider wird losgeschickt, um die Seite zu durchsuchen und jedem Link zu folgen. Screaming Frog bietet außerdem die Möglichkeit, Daten als CSV Tabelle zu exportieren.
Nachteile von Screaming Frog SEO SpiderDie lokale Installation kann ein Nachteil sein, da das Tool dadurch nur über den Desktop PC nutzbar ist. Screaming Frog prüft keine Backlinks und enthält kein Keyword Monitoring. Obwohl das Tool sehr viele Funktionen bietet, ist durch die Benutzeroberfläche nicht alles schnell und einfach zu finden. Eine Übersicht in Form eines Dashboards ist nicht vorhanden. Die zeitliche Planung von Crawls ist nicht einstellbar, da kein Projekt angelegt wird, sondern die Analyse durch die Eingabe einer URL startet.
Beste Funktionen von Screaming Frog SEO SpiderÜberprüfung von
– Duplicate Content
– eingehenden und ausgehende Links
– Status Codes und Redirects
– Meta Daten
Analyse in wenigen Sekunden möglich, übersichtlich (wenn man weiß, wo man was findet), umfangreicher Onsite-Check, sehr leicht zu lernen.
„Ein EKG für Deine Webseite – Bestandsaufnahme.“
Stefanie Lasch
E-Commerce Manager (SEO)
123
Extrem vielfältig wenn man sich mal etwas eingelebt hat, einfach ein tolles SEO-Toll für wenig Geld. Ideal für Leute die SEO-Analysen machen für mehrere Domain oder eine sehr grosse Seite betreuen.
Nachteile von Screaming Frog SEO SpiderEtwas beängstigend man es noch nicht gut kennt, die 1’000 Funktionen & Anpassungen können echt überfordern.
Beste Funktionen von Screaming Frog SEO SpiderFür Status-Kontrollen, Page-Title & Metadescripiton Optimierungen, Weiterleitungen
Allgemeines Fazit zu Screaming Frog SEO SpiderSehr vielfältig einsetzbar.






Screaming Frog SEO Spider Testberichte
Screaming Frog Tooltest – ein Guide für nicht-technische SEOs
Account erstellen
Screaming Frog erlaubt es Dir in der kostenfreien Version, bis zu 500 URLs auf einmal zu crawlen. Das ist eine gute Möglichkeit, das Tool auf seinen Nutzen für Deine Website zu testen. Anders als bei anderen SEO-Tools ist der Preis für Screaming Frog durchaus moderat. Eine Lizenz kostet £149 pro Jahr, also ca. 165€. Hast Du die Lizenz erworben, kannst Du das Tool mit der Google Search Console und Analytics verknüpfen und damit unkompliziert herausfinden, welche Deiner meistbesuchten und sichtbarsten Seiten besonders häufig und intensiv überprüft werden sollten.
Um zu starten, musst Du die Screaming Frog Software herunterladen. Zunächst macht das Tool vielleicht einen etwas unübersichtlichen Eindruck – vergleichbar mit einem Flugzeug-Cockpit, in dem man nicht genau weiß, welche Funktion welcher Button haben könnte.
Gib eine URL in die Suche ein und drücke auf Start, um zu überblicken, welche Daten das Tool dann verarbeitet und darstellen kann.
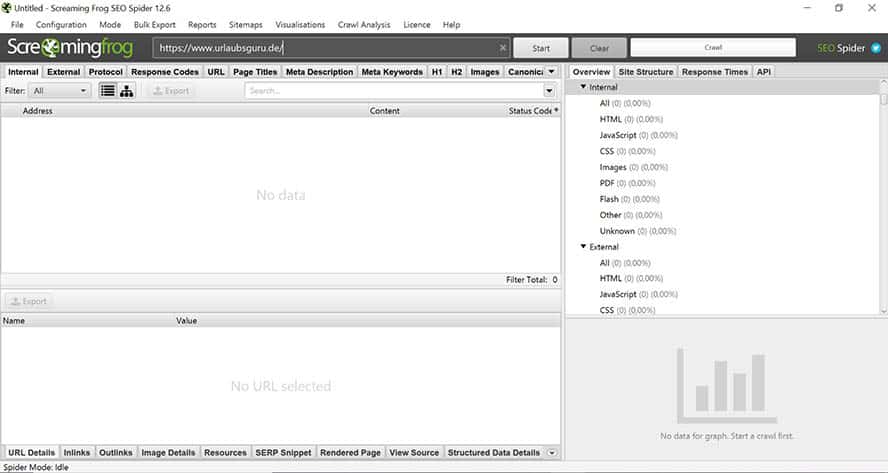
So sieht Dein Screaming Frog Dashbord aus.
5 Tipps, wie Du Screaming Frog optimal nutzt
1. Kompletter Crawl oder Prüfung einiger URLs
Wenn Du einen gesamten Audit der Webseite machen willst, macht es Sinn, Deine Seite von oben bis unten einmal komplett zu crawlen. Dann lass die sogenannte SEO Spider ausgehend von einer URL einmal alle URLs der Website mit all seinen Verzeichnissen und Links untersuchen. Um es dem Tool und auch Deinem Server etwas leichter zu machen, kann dazu die Geschwindigkeit des Crawls angepasst werden. Zusätzlich können weniger relevante Elemente wie Bilddateien vom Crawl ausgeschlossen werden.
Wenn Du nur eine Auswahl bestimmter URLs prüfen möchtest, kannst Du unter „Mode“ im Menü den Punkt „Upload“ auswählen und dann entweder aus einer Datei URLs hochladen, diese manuell eintragen oder bestimmte Seiten via Copy & Paste einfügen.
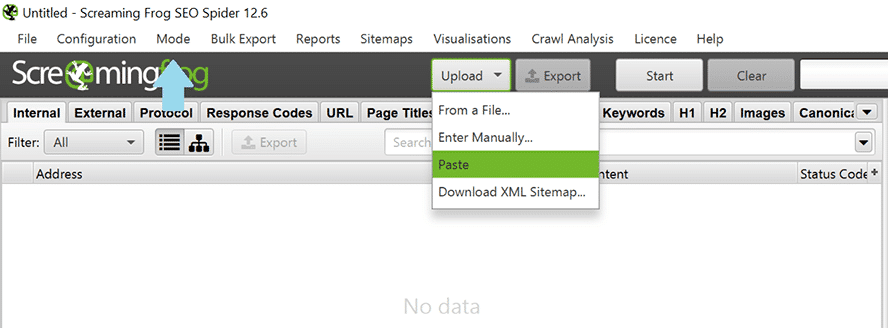
So kopierst Du eine Liste mit URLs für die Analyse.
2. Einstellung des Screaming Frog SEO Spider
Die Voreinstellungen des Tools sind ähnlich wie es bei einem Google Bot sein würde. Wenn Du nichts an diesen Einstellungen veränderst, wird dein Crawl unkompliziert laufen und sinnvolle Ergebnisse hervorbringen. Mit einigen Tipps kannst Du allerdings Dein Tool ganz nach Deinen Vorstellungen konfigurieren und so deutlich genauere Ergebnisse für Deinen Bedarf erzielen.
Wähle im Menü den Punkt „Configuration“ aus und inkludiere bzw. exkludiere, welche Art von Ressourcen, Links und Crawl-Eigenschaften Du nutzen möchtest.
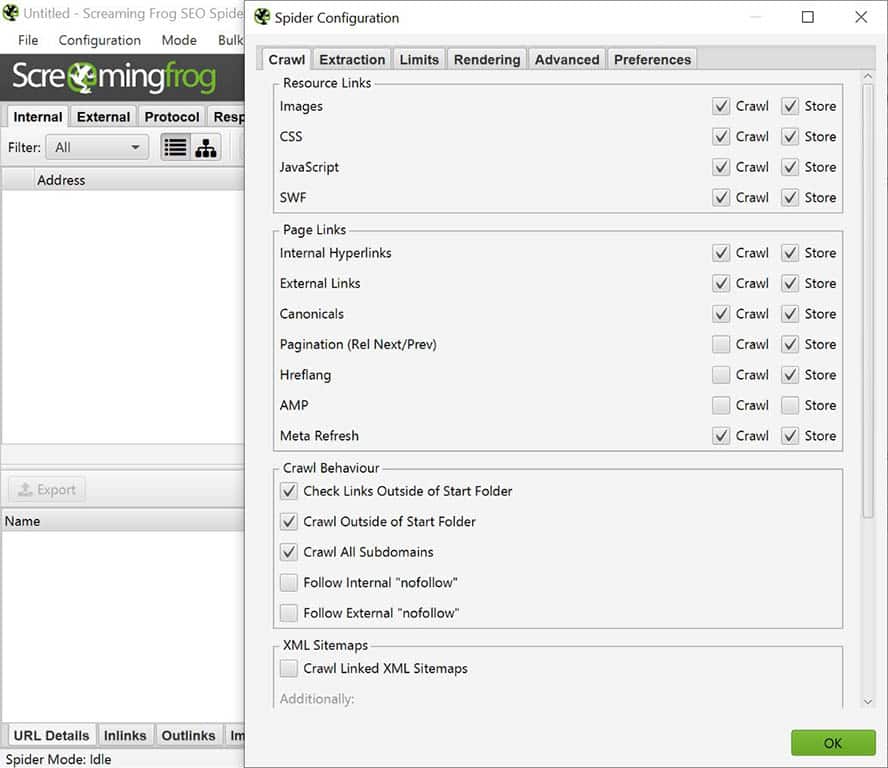
So stellst Du ein, welche Elemente Deiner Seite gecrawlt werden sollen.
Du kannst wählen zwischen „Crawl“ und „Store“:
- Crawl meint hier, dass mit Anklicken der Checkbox die ausgewählten Elemente in die Prüfung inkludiert werden.
- Store bedeutet, dass diese Elemente dann auch in Deinen Ergebnissen dargestellt und gespeichert werden.
Wenn das Spider Tool nur Seiten- und Textelemente betrachten soll, können Scripte und Medien-Elemente (Bilder, CSS, Javascript, SWF) hier exkludiert werden.
3. Die richtige Auswahl der Daten
Es können unglaublich viele unterschiedliche Daten Deiner Website für Dich gespeichert werden. Wenn du keine vorherige Auswahl triffst, bekommst Du also eine schier unendliche Darstellung unterschiedlicher Tabs mit mehr oder weniger hilfreichen Informationen und Daten. Suche deshalb im Vorfeld aus, welche Infos du wirklich brauchst, um dir eine komplizierte Analyse im Nachgang zu ersparen.
Gehe dazu auf „Configuration“ und in den Tag „Extraction“. Dort lassen sich dann via Checkbox diverse Daten auswählen. Weniger ist da häufig mehr.
Tipp: Strukturierte Daten (JSON-LD & SCHEMA.org Validation) sind nicht automatisch eingestellt, diese müssten bei Bedarf extra ausgewählt werden.
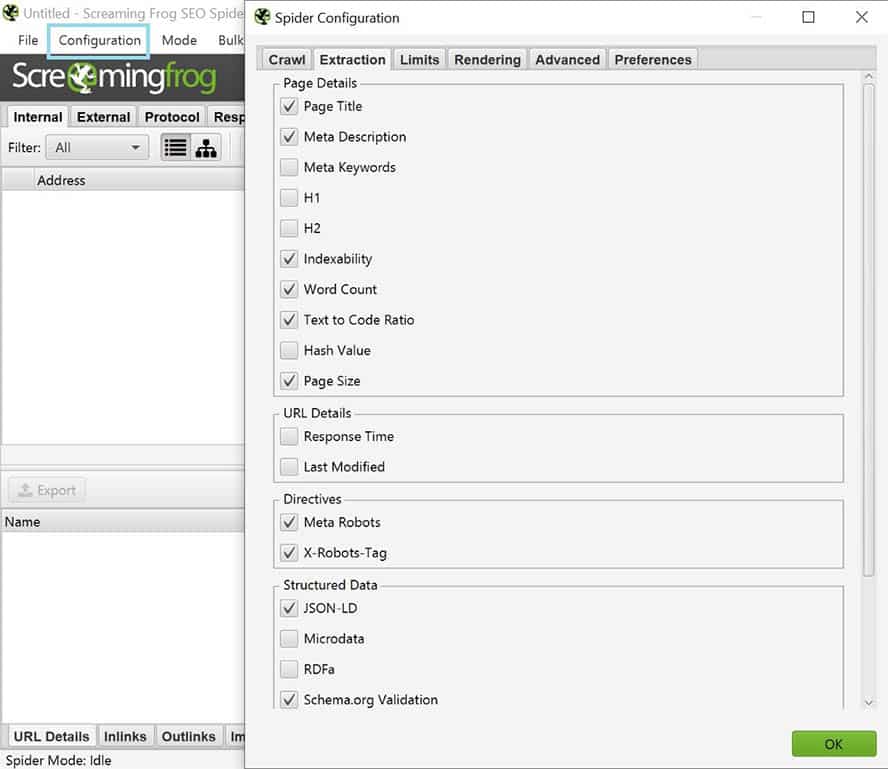
Konfiguriere die Daten, die Du analysiert haben möchtest.
4. Saubere Daten
Um ein noch genaueres Ergebnis zu erzielen, ist es hilfreich, die Funktion „URL rewriting“ zu nutzen.
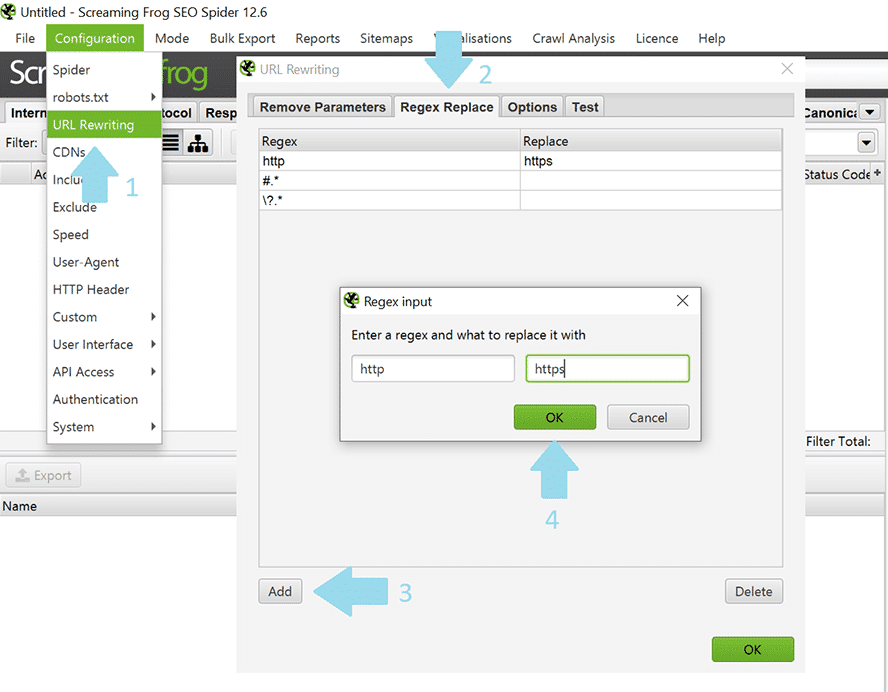
Nutze die “URL rewriting” Funktion, um übersichtliche Daten zu erhalten.
Dazu muss hier unter „Configuration“ der Punkt „URL rewriting“ ausgewählt und dort im Tag „Regex Replace“ die überflüssigen URL-Zusätze entfernt werden.
- Alle voreingestellten Parameter können, wie im Screenshot dargestellt, entweder ersetzt oder freigelassen werden. Um die Parameter zu entfernen, müsst ihr \?.* eingeben, um eine saubere URL ohne Zusatz zu erhalten. .* \
- Wenn Du eine URL mit einer Hash-Endung vorliegen hast, musst du den Befehl #.* eingeben, um die nachstehenden Hash-Zusätze zu entfernen.
- Http sollte in https umgewandelt werden, weil sonst beide in der Auswertung erscheinen. Wichtig hierbei: Nutze diese Funktion nicht, wenn Du Dir vom Crawl eine Übersicht über genau die URLs verschaffen willst, die noch mit http statt https versehen sind.
Um zu prüfen, welche Ergebnisse Dir angezeigt werden und ob es eventuell noch Justierungsbedarf gibt, kannst Du den Tab „Test“ nutzen, um Dir anzusehen, ob die Ergebnisse mit Deinen bisherigen Einstellungen so passen.
5. Verknüpfung von Screaming Frog mit der Google Search Console und Analytics
Die richtige Priorisierung ist eine der wichtigsten Aufgaben im SEO-Bereich. Es gibt immer neue Kampagnen und Seiten zu analysieren. Um einen guten Überblick über alle relevanten URLs zu haben, macht die Verknüpfung mit Google Analytics und der Google Search Console Sinn.
Dann kannst Du Dir einen konkreten Plan der wichtigsten Aufgaben machen und diese nach Sichtbarkeit und Suchvolumen abarbeiten. Wenn Du weitere Tools wie Ahrefs oder MOZ nutzt, sind auch diese hier gut verknüpfbar.
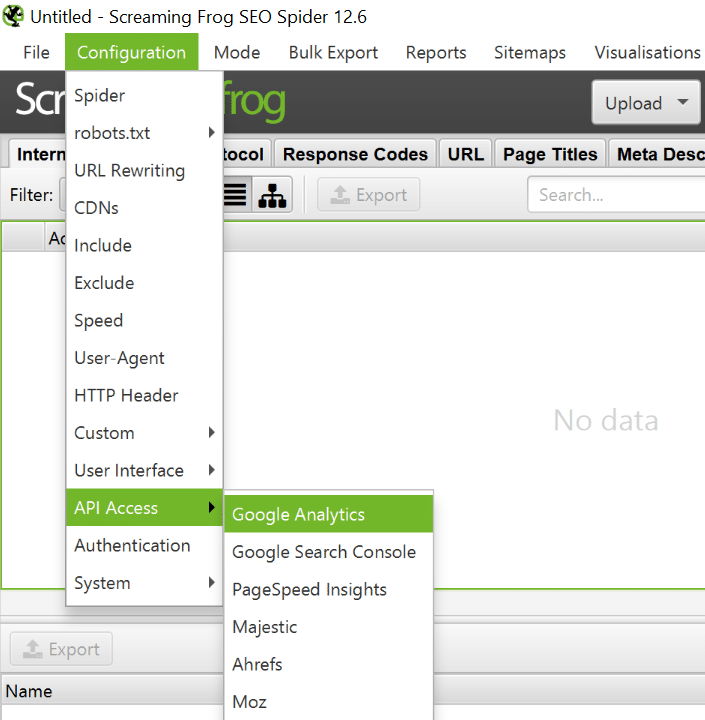
So verknüpfst Du Screaming Frog mit APIs wie Google Analytics.
Analyse und Export von Daten
Sobald Du einen Crawl gestartet hast, fliegen auch schon die ersten Daten herein. Warte, bis die Analyse zu 100% abgeschlossen ist, bevor Du mit der tiefergehenden Analyse beginnst. Um die Ergebnisse bestmöglich zu überblicken, solltest Du einige der zahlreichen Filterfunktionen nutzen, die Dir Screaming Frog bietet.
Zum Beispiel hast Du die Möglichkeit, alle Daten ganz einfach zu exportieren (s. Screenshot).

So exportierst Du die erhobenen Daten.
Ergebnisse können außerdem direkt aus dem Dashboard kopiert werden. Dort findest Du drei große Panels.
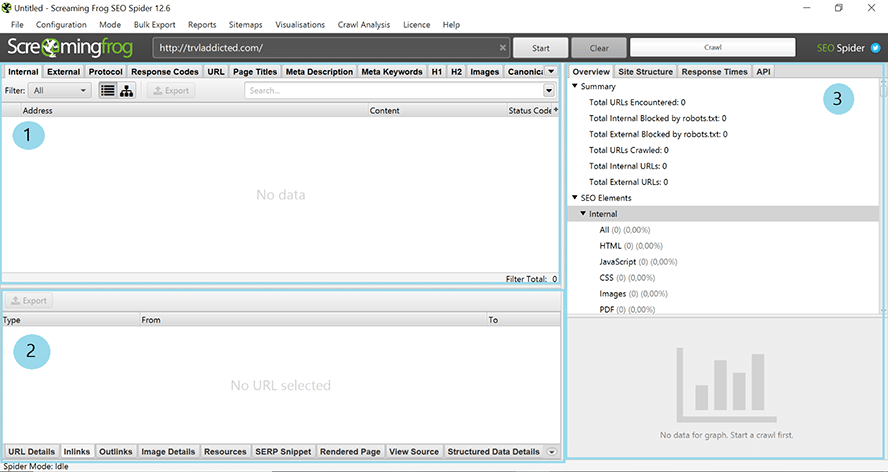
Das Dashboard besteht aus drei Teilen.
- Oben rechts im Panel (1) findest Du alle gecrawlten URLs – inklusive allem, was damit zusammenhängt. Hier erscheint zum Beispiel der Statuscode, der Seitentitel, die Meta-Beschreibung und mehr.
- Klickst Du im ersten Panel auf eine URL, erscheinen im unteren Panel (2) dann detaillierte Informationen, die Dir dann noch weitere, hilfreiche Infos zu dieser ausgewählten URL bieten können.
- Im rechten Panel (3) bekommst Du dann nochmal einen Überblick über den Crawl – zum Beispiel über die Anzahl der geprüften URLs, Verlinkungen und mehr.
Diese fünf Dinge kannst Du u.a. mit Screaming Frog analysieren
Es gibt zahlreich Themen und Probleme, die mit dem Tool erkannt und hervorgehoben werden können. Einige davon sind für die tägliche Arbeit besonders relevant, deshalb werden sie hier extra hervorgehoben. Behalte nur im Hinterkopf, dass das Tool darüber hinaus noch viele weitere Möglichkeiten bietet.
- 404-Statusinfo
- Weiterleitungsketten
- Snippet-Analyse
- Strukturierte Daten
- Personalisierte Suche
1. 404- Statusinfo und kaputte Links
Um kaputte Links mit einen 404-Status schnell und einfach herauszufiltern, nutze diese 4 einfachen Schritte:
- Wähle „Response Codes“ im Menü aus
- Nutze den Filter „Client Error 4xx“ im Drop Down Menü
- Wähle die zu analysierende URL
- Klick im unteren Panel auf „Inlinks“, um Dir die kaputte URL anzeigen zu lassen
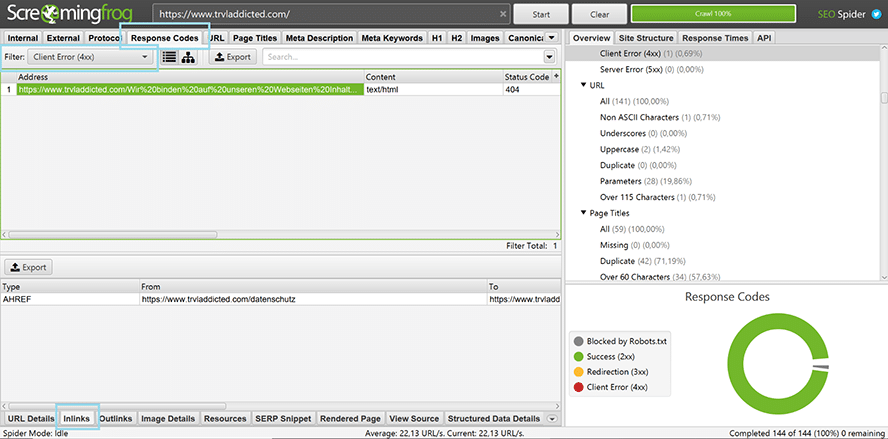
So findest Du 404 Fehler bei Screaming Frog.
Im Screenshot oben kannst Du sehen, dass eine URL der Webseite TRVLaddicted.com einen kaputten Link aufweist. Offensichtlich funktioniert der Link auf die Datenschutz-Seite nicht und muss gefixt werden.
2. Weiterleitungsketten
Weiterleitungen sind hilfreich, wenn sich Inhalte ändern, Projekte vergrößern oder Themen nicht mehr angezeigt werden sollen. Im Laufe der Zeit entstehen dann häufig ganze Ketten aus Weiterleitungen, bis der User dann letztendlich auf der für das Thema aktuell wichtigsten Seite landet. Innerhalb des Tools habt ihr die Möglichkeit, euch alle Weiterleitungen genauer anzuschauen und deren Sinn unter die Lupe zu nehmen. Wer mit contentreichen, dynamischen Webseiten arbeitet, weiß, wie schwer es ist, da einen Überblick zu behalten. Lange Weiterleitungsketten sorgen für längere Ladezeiten, die bekanntlich kein User gerne erlebt.
So erkennst Du Weiterleitungsketten
- Wähle im Menü „Response Codes“ aus.
- Filtere nach „Redirection 3xx“.
- Klicke auf die URL, die Du fixen möchtest.
- Schaue Dir im unteren Panel dann unter dem Tag „URL Details“ oder „Outlinks“ an, wohin die Seite geleitet wird.
- Prüfe im Tab „Inlinks“, welche Seite auf die alte URL führt und wähle, welche neue URL sich da sinnvoller anbietet.
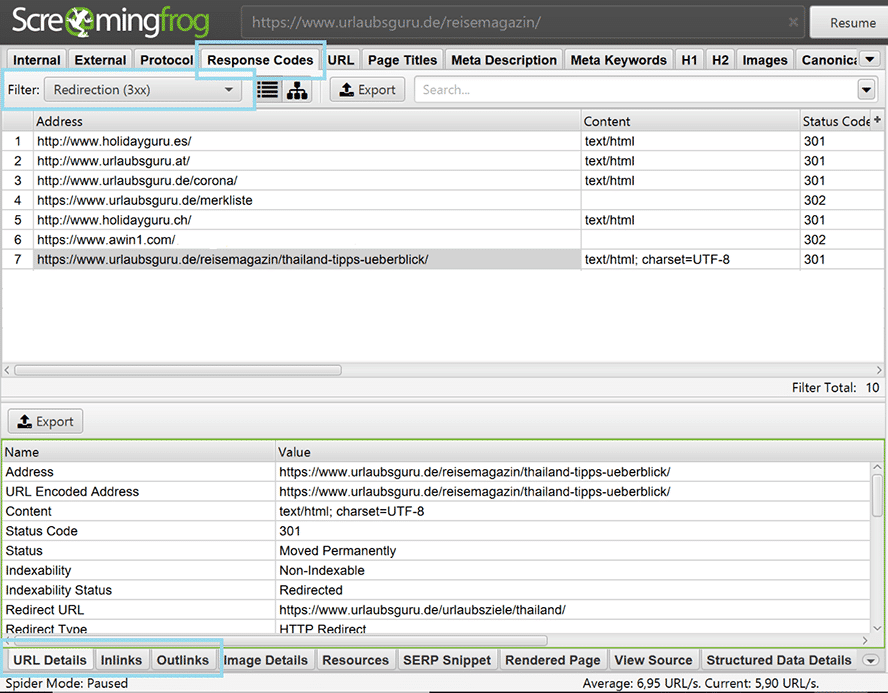
So findest Du Weiterleitungsketten bei Screaming Frog.
Im Screenshot oben kannst Du sehen, dass die URL https://www.urlaubsguru.de/reisemagazin/thailand-tipps-ueberblick/ permanent umgeleitet wurde (301-Status). Im unteren Panel siehst Du, dass die neue URL https://www.urlaubsguru.de/urlaubsziele/thailand/ lautet. Unter „Inlinks“ siehst Du dann, welche URLs noch auf die alte Seite führen. Hier sollten dann entsprechend die alten Links zeitnah getauscht oder umgeleitet werden.
3. Snippet-Analyse
Snippets sind für viele User der erste und wichtigste Berührungspunkt mit der Marke, dem Produkt oder der gesuchten Information. Deshalb ist es sehr relevant, deren Performance regelmäßig zu prüfen und sicherzustellen, dass der User auf den ersten Blick alle Infos bekommt, die er benötigt. Screaming Frog hilft dabei, alle Snippets auf ihre Länge zu prüfen, zeigt an, welche Seiten gar kein Snippet haben und kann helfen, doppelten Content zu erkennen.
So analysierst Du Snippets mit Screaming Frog.
4. Strukturierte Daten
Eine gute Möglichkeit, bessere Sichtbarkeit zu generieren, ist es, strukturierte Daten zu Deinen wichtigsten Seiten hinzuzufügen. Besonders sinnvoll sind dabei FAQs und strukturierte Produktdaten. Das Tool kann dabei helfen, herauszufiltern, an welchen Stellen Du FAQ und Co. noch einfügen könntest und wo es Fehler gibt. Dazu muss eine bezahlte Lizenz erworben werden.
Wichtig: Stelle vor dem Crawl sicher, dass Du die Checkboxen für Structured Data bei der Konfiguration (s. o. Die richtige Auswahl der Daten) eingestellt hast.
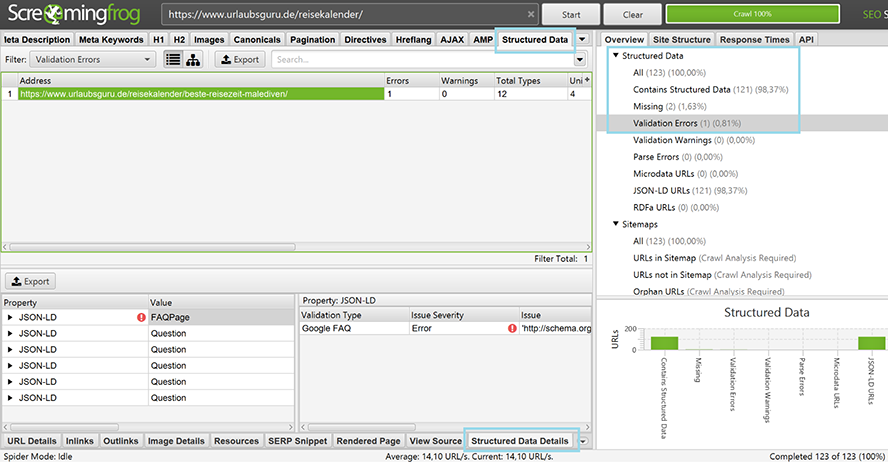
So findest Du Fehler in den strukturieren Daten.
Nach dem Crawl nutzt Du dann im Datensheet den Tab „Structured Data Details“. Dort werden dann alle URLs angezeigt, die bereits strukturierte Daten enthalten.
Im Beispiel ist im Panel auf der rechten Seite zu sehen, dass 123 URLs des Verzeichnisses https://www.urlaubsguru.de/reisekalender/ geprüft wurden. Davon verfügen bereits 121 über Structured Data, bei 2 URLs gibt es noch Nachholbedarf und bei einer URL wird ein Fehler angezeigt.
Um dies genau zu prüfen, sind folgende Schritte sinnvoll:
- Klicke auf den Tab „Structured Data“
- Prüfe im rechten Panel die Anzahl der gecrawlten URLs und dort dann weiterhin, welche davon bereits strukturierte Daten beinhalten
- Filtere „Validation Errors“ heraus
- Wähle oben die URL aus, die Du analysieren möchtest
- Schaue danach im unteren Panel, nach den „Structured Data Details“ und prüfe, wie sich die Seite optimieren lässt
5. Personalisierte Suche
Die personalisierte Suche nutzt Du, um spezielle Keywords auf der Webseite zu finden. Das ist zum Beispiel sinnvoll, wenn sich alte Nutzungsmodalitäten ändern und Du sicherstellen willst, dass überall entsprechender Content an neue Nutzungsbedingungen angepasst werden kann.
Die Suchfunktion ist außerdem hilfreich, wenn Du checken möchtest, ob auch wirklich überall eine Google Tag Manager ID verwendet wird oder ob zum Beispiel auf Deinen Produktseiten Angebote sind, die aktuell nicht mehr verfügbar sind.
Um die Suche sinnvoll zu nutzen, kannst Du folgendermaßen vorgehen:
- Wähle „Configuration“ > „Custom“ > „Search“ > „Add“
- Wähle “Contain”, wenn Du nach Inhalten suchen möchtest, die bestimmte Keywords enthalten
- Wähle „Does not Contain“, wenn Du sehen willst, auf welchen Seiten bestimmte Keywords noch fehlen
- Jetzt kannst Du alle möglichen Suchbegriffe eingeben – es sind bis zu 100 Einträge möglich
- Starte den Crawl
- Im Tab „Custom Search“ findest Du im Top Panel jetzt die Seiten, in denen Dir Inhalte fehlen oder eben nicht. Je nachdem, was Du eingestellt hast.
Nutze die personalisierte Suche, um nach Inhalten innerhalb deiner Webseite zu suchen.
Pro und Kontra – Screaming Frog
Wie Du siehst, gibt es zahlreiche Möglichkeiten, Deine Website auf alle möglichen Weisen zu analysieren.
Pro
- Das Screaming Frog Spider Tool kann so gut wie alle Daten abfragen und stellt diese sinnvoll und gut filterbar dar
- Die Verknüpfung mit Google Analytics und der Search Console ist ein dickes Plus
- Der Preis für die Jahresnutzung ist top – vor allem für die Daten, die man dafür erhält
Kontra
- Die Oberfläche ist auf den ersten Blick nicht besonders intuitiv
- Für SEO-Beginner ist das Tool zunächst sehr kompliziert
Fazit
Screaming Frog ist eines der wichtigsten und hilfreichsten Tools für SEOs, die es derzeit auf dem Markt gibt. Es hat den klaren Zweck, die Suchmaschinenoptimierung zu vereinfachen, valide Daten zu liefern und alle möglichen Optimierungsmöglichkeiten aufzuzeigen. Das Tool wird regelmäßig mit neuen hilfreichen Updates versehen und ist so immer am Zahn der Zeit.
Die schier unendliche Datenmenge, die sich mit Screaming Frog abfragen lässt, kann kombiniert mit der unhandlichen Oberfläche zunächst etwas überfordern, doch mit den passenden Priorisierungen und Filtermöglichkeiten wird es schnell zu einem hilfreichen Werkzeug für den SEO-Alltag.
Lass Dich vom ersten Overload an Möglichkeiten nicht abschrecken und versuche, immer im Blick zu behalten, dass es wichtig ist, nicht nur die Daten sinnvoll zu filtern, sondern auch eine klare Priorisierung der eigenen Landingpages und Verzeichnisse vorzunehmen. Dann entwickelt sich Screaming Frog zu einem echten Helfer im Wust der URLs.
Autor
Astrid Klaver

Astrid Klaver arbeitet als Inhouse SEO bei der Urlaubsguru GmbH. Hier ist Sie verantwortlich für die Optimierung des niederländischen & spanischen Holidayguru Projekts. Ihre Hauptexpertise liegt im On-page SEO und sie hat ein besonderes Interesse für das Thema Digitale PR.
Relaunch mit dem Screaming Frog
Vermeide Fehler beim Relaunch und visualisiere Deine Webseitenstruktur mit dem Screaming Frog
Wer Suchmaschinenoptimierung (SEO) betreibt, dürfte schon mal von dem schreienden Frosch (Screaming Frog SEO Spider) gehört bzw. gelesen haben. Grundsätzlich gilt: Tools im Bereich der Suchmaschinenoptimierung gibt es wie Sand am Meer. Schnell verlieren insbesondere SEO-Neulinge den Überblick. Das ist nichts Ungewöhnliches und auch nicht schlimm. Wir haben alle mal bei Null angefangen. Den schreienden Frosch sollte man sich meines Erachtens aber auf jeden Fall widmen, und ihn ausgiebig testen. Ich bin sicher, die Fülle an Features überzeugt und macht ihn zu einem festen Bestandteil in der täglichen Arbeit. Gerade für jene, die von der zentralen Bedeutung des Onpage-SEO überzeugt sind.
Was ist der Screaming Frog?
Der Screaming Frog SEO Spider ist ein lokal auf dem Rechner installiertes Tool, mit dem sich in Echtzeit einzelne URLs oder ganze Webseiten crawlen lassen. Der Screaming Frog durchläuft, wie der Google Bot die eingetragene Seite. Es ist hierbei egal, ob es sich um die eigene Internetseite handelt oder eine x-beliebige Seite im Web. Mit dem Screaming Frog könnten somit auch interessante Informationen über die Seiten der Mitbewerber ermitteln werden.
Abbildung 1: Der Screaming Frog nach dem Start
Der Bot des Screaming Frog folgt allen internen Links, ruft jede URL auf und sammelt zahlreiche Informationen. So listet das Tool nach dem Crawl zum Beispiel Informationen über die Meta Angaben, die Statuscodes, die internen Links, die Dateigrößen, Canonical-Links, hreflang und noch vieles mehr auf.
Den Screaming Frog gibt es in zwei Versionen. In der kostenlosen Version bietet er sich gut für kleine Webseiten an. Bis zu 500 URLs sind in der kostenlosen und abgespeckten Version crawlbar.
In dieser eingeschränkten Version ist es zum Beispiel nicht möglich, den Crawler zu konfigurieren, die Crawl-Ergebnisse abzuspeichern, Seiten zu rendern, Informationen zu strukturierten Daten zu erhalten oder Google Analytics und die Search Console zu verbinden.
Wer größere Seiten und somit mehr crawlen und Informationen erhalten möchte, benötigt eine Lizenz. Diese kostet 149 £ pro Jahr und Nutzer. Die kostenpflichtige Version lohnt sich in der Regel – vor allem im Vergleich zu den Lizenzkosten anderer Tools.
Was der Screaming Frog nicht kann
Seit Jahren klingen „Content ist King“ und „WDF*IDF“ durch die SEO- und Online-Marketing-Szene. Beides sind Schlagworte, mit denen der schreiende Frosch wenig anfangen kann. Der Screaming Frog analysiert nicht den Inhalt, also den Content, einer Seite. Er kann somit keine Bewertung des Inhaltes auf Sinn, vorgesehenes Keyword-Set und der verfolgten Ziele vornehmen.
Der Screaming Frog bietet auch keine Lösungen zur Optimierung der Seite. Er sammelt lediglich zahlreiche Informationen. Um eine Seite für die Suchmaschinen zu optimieren, gilt es die richten Schlüsse und somit To-dos auf Basis der erhaltenen Informationen zu ziehen.
Wer den Screaming Frog SEO Spider zum ersten Mal benutzt, wird von dem nüchternen Erscheinungsbild überrascht sein. Wer bunte Grafiken erwartet, dürfte enttäuscht sein. Seit dem Update auf die Version 10.0 gibt es den Menü-Punkt „Visualisations“. In diesem Bereich werden die gesammelten Informationen mit interaktiven Diagrammen dargestellt. Eine der wenigen Stellen, an denen Farbe in die Auswertung kommt. Eine Randbemerkung an dieser Stelle: Mittlerweile gibt es die Version 11.3 (Stand August 2019).
Was solltest Du vor dem Crawlen beachten?
Je größer eine Seite ist, desto wichtiger ist es, das Crawling zu steuern. Wie bereits erwähnt, analysiert er die angegebene Seite in Echtzeit und beschäftigt somit deren Server. Ein Crawl bindet zudem Kapazitäten des Rechners. Überlege also vor dem Crawl genau, was gecrawlt werden soll. Zur „Entlastung“ des Servers kann einerseits die Crawl-Geschwindigkeit („Configuration“ > „Speed“) eingestellt werden. Weithin können auch nur bestimmte Seiten sowie Ordner ein- oder ausgeschlossen („Configuration“ > „Include“/“Exclude“) werden.
Abbildung 2: Durch entsprechende Einstellungen lässt sich der Server „entlasten“
Wie der Crawler im Detail konfiguriert werden kann, soll allerdings nicht Teil dieses Artikels werden. Eine ausführliche Beschreibung liefert der Screaming Frog selbst („Help“ > „User Guide“).
Zudem gibt es geschätzte Kollegen in der Szene, wie zum Beispiel Markus Hövener, die viele Tipps und Tricks zum Screaming Frog veröffentlichen (https://blog.bloofusion.de/screaming-frog-hacks/).
Was mit dem Screaming Frog möglich ist
- Seitentitel und Metabeschreibungen analysieren diejenigen erkennen, die zu lang, zu kurz und doppelt sind oder sogar gänzlich fehlen.
- Informationen über Indexierungsstatus, Dateigrößen, Antwortzeit des Servers, Textumfang, Verhältnis Text zu Code, interne und externe Links, Ankertexte der internen Links, Canonical Links,… erhalten.
- Exakt doppelte URLs (md5-Algorithmusprüfung) oder doppelte Elemente wie Seitentitel, Beschreibungen und Überschriften erkennen.
- Defekte Links (Statuscode 404) und Serverfehler finden.
- Nach temporären und permanenten Weiterleitungen suchen und Weiterleitungsketten und -schleifen identifizieren.
- URLs anzeigen lassen, die von robots.txt-, Meta-Robots- oder X-Robots-Tag-Direktiven wie ‘noindex’ oder ‘nofollow’ blockiert werden.
- SERP-Snippets analysieren und optimieren.
- Verbindung zur Google Analytics-API herstellen und weitere Daten zu den analysierten Seiten abrufen.
- Webseiten mithilfe des integrierten Chromium WRS rendern. Aber Vorsicht: Wenn JavaScripts gecrawlt werden, wird der Crawl langsamer. Dieses Feature sollte immer nur gezielt eingesetzt werden.
- Site-Architektur mithilfe interaktiver Diagramme visualisieren und die interne Verlinkung und URL-Struktur bewerten.
- Verschiedenste Informationen in csv-, xls- oder xlsx-Dateien exportieren und in Excel weiterverarbeiten.
- Komplettes Ergebnis einer Analyse abspeichern und es später wieder aufrufen. Der Crawl einer Seite muss somit nicht immer neu für eine Seitenanalyse ausgeführt werden.
Ist das schon alles?
Die Aufzählung skizziert nur einen Teil der konkreten Einsatzmöglichkeiten des Screaming Frog SEO Spider. Durch seine stetige Weiterentwicklung können immer mehr individuelle SEO-Fragestellungen beantwortet werden.
Damit Suchmaschinen eine Webseite besser „verstehen“ sind strukturierte Daten ein wichtiger Bestandteil beim Onpage-SEO. Der Screaming Frog bietet die Möglichkeit, die per JSON-LD, Microdata oder schema.org ausgezeichneten Daten zu überprüfen.
Hilfreich ist das Tool zum Beispiel auch bei einem Relaunch der Website. Gerade bei größeren Webseiten kann es vorkommen, dass bei der Einrichtung von Weiterleitungen URLs vergessen werden. Nach dem Relaunch würden Links zu deren Seiten im Nichts landen und 404-Seiten zur Folge haben. Dies kann unter Umständen wiederum den Verlust von wichtigen Rankings und der Sichtbarkeit bedeuten.
Wie der Screaming Frog bei einem Relaunch eingesetzt werden kann, wird im weiteren Verlauf beleuchtet.
Mit dem Screaming Frog (in Verbindung mit anderen Tools und Browser-Erweiterungen) sind auch spannende Hacks möglich. So konnte zum Beispiel Alexander Holl von 121WATT herausfinden, in welchen italienischen Restaurants in München er an Silvester 2018 den Jahreswechsel feiern konnte.
Youtube-Video von Alexander Holl (https://www.youtube.com/watch?v=fFdoubZhCSc)
Alternativlos?
Für viele ist der Screaming Frog zu einem beliebten und sehr häufig genutzten Tool in der täglichen Arbeit geworden. Mit Sicherheit auch auf Grund seiner Fülle an Features und Einsatzmöglichkeiten. Alternativlos ist er deswegen aber nicht. Mit RYTE, Sitebulb und Deepcrawl gibt es vergleichbare Tools. Jedes hat für sich Vorteile und wiederum Nachteile gegenüber den anderen Tools. Auch SEO-Tools wie Sistrix, Searchmetrics, Xovi und Co. bieten Onpage-Analysen an.
Redirect-Audit beim Website-Relaunch mit dem Screaming Frog
Ein Website-Relaunch muss nicht nur optische Veränderungen mit sich bringen. Grund für einen Relaunch könnten auch die Überarbeitung und Neukonzeption von Inhalten, die Vereinfachung der Navigationsstruktur oder auch die Optimierung der Geschwindigkeit des eingesetzten Content-Management-Systems (CMS) sein. Oftmals kommen viele Gründe zusammen. Aus SEO-Sicht ist ein Relaunch daher eine spannende Angelegenheit. Aber Vorsicht! Auf dem Weg eines Website-Relaunch verbergen sich einige Fallstricke. Diese können weitreichende negative Folgen haben.
Gefahrenpotenzial besteht bei fehlenden oder fehlerhaften Weiterleitungen von den alten auf die neuen Inhaltseiten. Dies hat zum einen zur Folge, dass Rankings verloren gehen und schlussendlich die Besucher auf der Website fernbleiben. Zum anderen geht der Linkjuice externer Links auf die alten URLs und somit für die ganze Website verloren.
Doch die Weiterleitungen sind nicht nur für Suchmaschinen wichtig. Auch für Nutzer sind sie wichtig, die alte URLs der Website aufrufen, beispielsweise über Links im Web oder Lesezeichen in ihrem Browser. Sie erwarten eine funktionierende Seite und landen ungern auf einer 404-Fehlerseite. Beides Szenarien, welche verhindert werden können.
Was also tun? Ein Redirect-Audit mit dem Screaming Frog! Dieses wird helfen, das Gefahrenpotenzial von Sichtbarkeits- und Rankingverlusten zu minimieren. Es hilft auch, die eigene Website von lästigen und langsamen internen Redirects zu befreien.
1. Bestandsaufnahme
Im ersten Schritt ist eine Bestandsaufnahme aller existierenden URLs der Website erforderlich. Mit dem Screaming Frog ist dies bequem und mit wenigen Schritten möglich. Damit er alle URLs findet, muss er richtig konfiguriert werden. Dies erfolgt über das Menü „Configuration“ > „Spider“.
Neben der Standard-Konfiguration sollte beim Crawl auch allen internen nofollow-Links gefolgt werden. Sofern vorhanden, sollten auch die Subdomains oder die AMP-Seiten gecrawlt werden. Wenn der Crawl in einem Verzeichnis startet wäre „Crawl Outside of Start Folder“ auszuwählen, so dass auch die Root-Seite beim Crawl berücksichtigt wird. Weiterhin ist zu empfehlen, dass Rel Next- und Rel Prev-URLs ebenfalls gecrawlt werden. Schlussendlich sollten hreflang-URLs mit einbezogen werden. Zu guter Letzt könnten die Links in der XML-Sitemaps berücksichtigt werden. Diese Einstellung ist jedoch nicht zwingend notwendig.
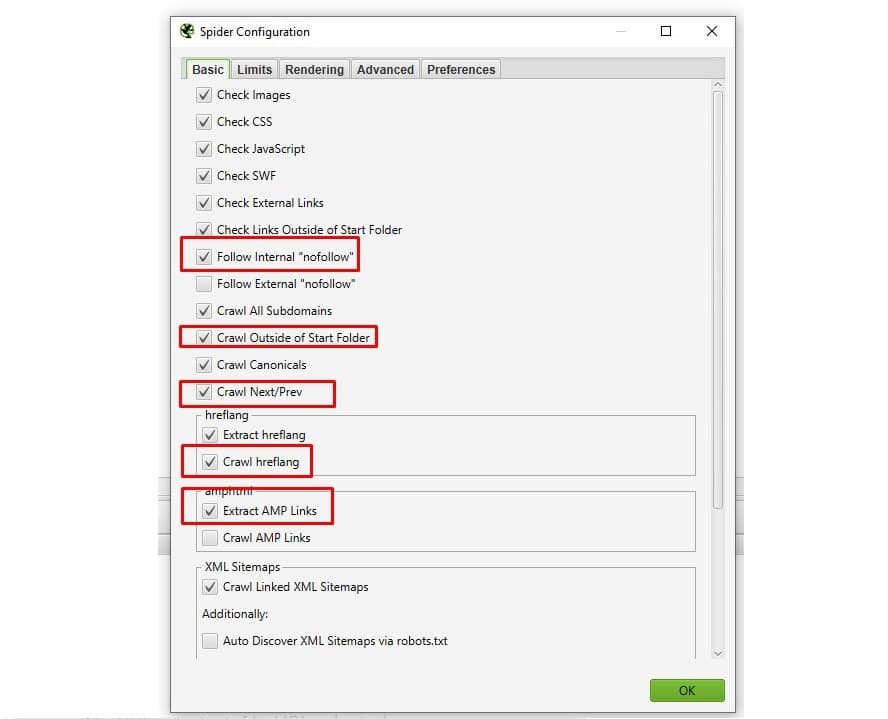
Abbildung 3: Wenn der Crawler aller URLs finden soll, sind ein paar Häkchen zusätzlich zu setzen
Je nach Größe der Website benötigt das Tool nun Zeit, um alle URLs zu crawlen. In der nun vom Screaming Frog erstellten Liste werden alle URLs aufgelistet, auch jene von z.B. PDF-Dateien und Bildern. PDFs und Bilder können bei Bedarf auch weitergeleitet werden. Wir konzentrieren uns an dieser Stelle auf die HTML-Seiten. Über den Filter (oben links) lassen sich nur diese anzeigen. Diese Liste kann wiederum als Excel-Datei oder auch als CSV-Datei exportiert werden.
Abbildung 4: Dropdown-Liste mit den Filtermöglichkeiten und dem „Export“-Button rechts daneben.
2. URL-Mapping
In Excel oder jedem anderen Tabellenverarbeitungsprogramm lässt sich dann das sogenannte URL-Mapping erstellen. Zu empfehlen ist hierbei eine Spalte für alle alten URLs. In der zweiten Spalte werden jene URLs vermerkt, auf die sie umgeleitet werden sollen.
Erstes Ziel sollte beim URL-Mapping sein, dass jede alte URL auf ein gleichwertiges Pendant weiterleitet. Zweites Ziel sollte sein, dass so wenig wie möglich auf die Startseite weitergeleitet wird. Warum? Weil die Startseite inhaltlich die alten URLs nicht wiederspiegeln und diese daher auf kurz oder lang aus dem Index fallen.
3. Weiterleitungen einrichten
Ist das URL-Mapping fertiggestellt, ist es an der Zeit, die Weiterleitungen vorzubereiten. Hierfür sollte die .htaccess-Datei auf dem Webserver bearbeitet werden. Zu empfehlen ist hier die sogenannte 301-Weiterleitung, da es sich um dauerhafte Weiterleitungen handelt. Bei vorübergehenden Weiterleitungen kommt eher ein 302-Redirect in Frage. Alte bzw. gelöschte Seiten, für die es nach dem Relaunch kein gleichwertiges Pendant gibt, sollten den HTTP-Statuscode 404 (not found) oder besser 410 (gone) zurückgeben. Google wirft diese URLs dann aus dem Index. Aber auch hier ist Vorsicht geboten. Bei URLs, welche viele externe Links besitzen, sollte es nicht angewendet werden, da der Linkjuice dann verloren gehen würde.
4. Kontrolle der Weiterleitung mit dem Screaming Frog
Wenn die neue Seite online ist, ist der Zeitpunkt gekommen, die eingerichteten Weiterleitungen zu prüfen. Hier kommt der Screaming Frog erneut zum Einsatz. Im ersten Schritt benötigen wir hierzu die vormals exportierte Liste der alten URLs. Zudem konfigurieren wir uns den Crawler erneut. Dies erfolgt wieder über das Menü „Configuration“ > „Spider“ und der Registerkarte „Advanced“. Der Crawler wird angewiesen, Redirects zu folgen.
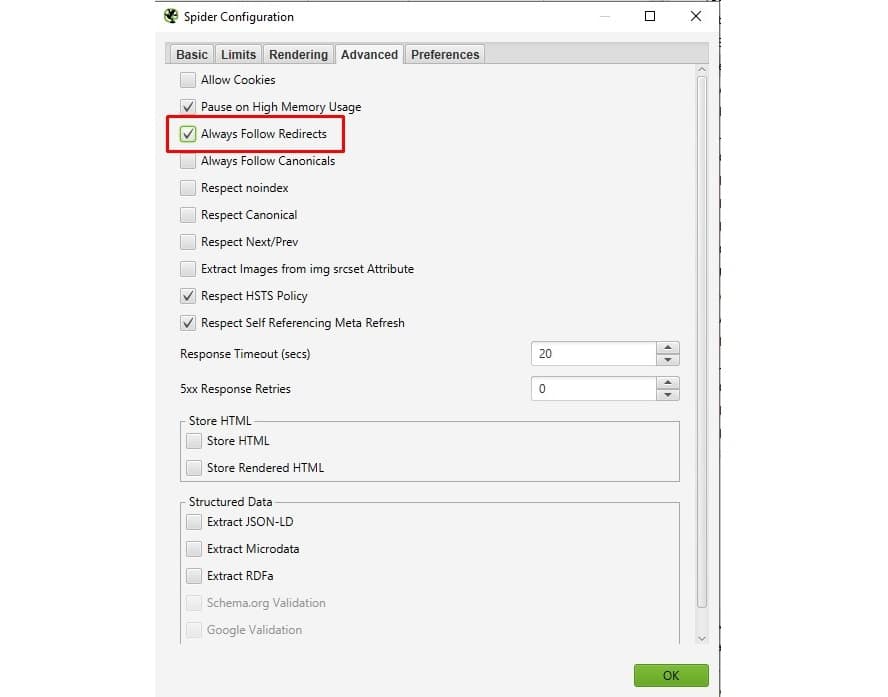
Abbildung 5: Redirects nicht nur erkennen, sondern ihnen bis zum Ende folgen
Als nächster Schritt wird in den Listenmodus gewechselt („Mode“ > „List“). Nun kann über den Button „Download“ manuell die Liste der alten URLs eingefügt und der Crawler gestartet werden. In diesem Modus werden lediglich die hochgeladenen URLs analysiert und keinen Links gefolgt, sprich mit der Crawltiefe null. Durch die entsprechende Anweisung „Always Follow Redirects“ bei der Konfiguration gibt der Screaming Frog nicht nur die Information, welchen Statuscode die jeweilige URL hat, sondern folgt den Weiterleitungen auch bis zum Ende. So werden zum Beispiel Weiterleitungsketten ermittelt.
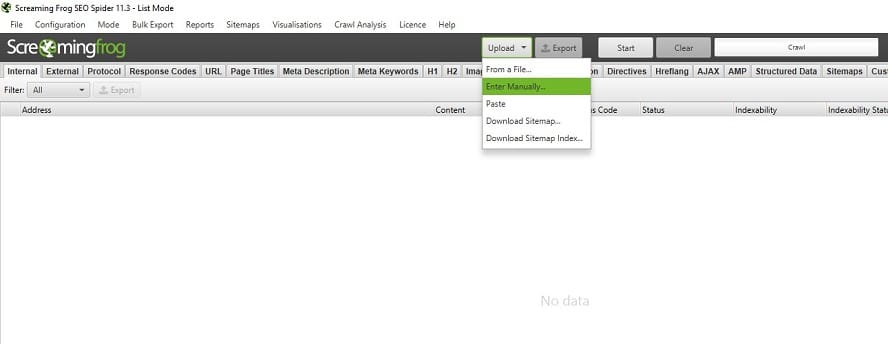
Abbildung 6: Unkompliziert kann eine Liste von URLs zum Crawlen geladen werden
Sobald der Screaming Frog den Crawl abgeschlossen hat, kann überprüft werden, ob alle Weiterleitungen soweit korrekt erfolgt sind. Hierzu wechseln wir in den Reiter „Response Code“ und filtern „Client Error (4xx)“. Sollte die Liste leer sein oder zumindest nur jene URLs auflisten, welchen wir den Statuscode 404 oder 410 gegeben haben, wurden keine gravierenden Fehler bei der Einrichtung der 301-Weiterleitungen gemacht.
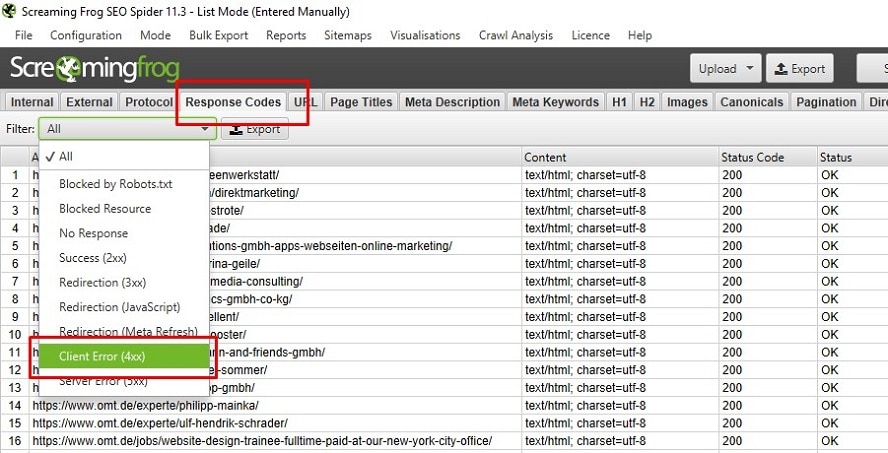
Abbildung 7: Schnell überprüfen, ob Redirects am Ende auf einer Fehlerseite landen
5. Weiterleitungsketten erkennen
Was bis zu diesem Punkt noch nicht bekannt ist: Gibt es Weiterleitungsketten oder andere Probleme mit den Weiterleitungen. Hierzu wird der Report „Redirects & Canonical Chains“ aufgerufen und exportiert.
In der Excel-Liste können nun alle Weiterleitungen nochmal nachvollzogen werden. Das Augenmerk sollte auf jene Zeile gerichtet sein, welche in der Spalte „Chain Type“ den Hinweis „mixed“ und oder in der Spalte „Redirect Loop“ ein „true“ stehen haben. In der Spalte „Number of Redirects“ wird angegeben, um wie viele Weiterleitungen es sich in der Kette handelt. Die detaillierten Informationen zu den Weiterleitungen findet sich in den nachfolgenden Tabellenspalten.
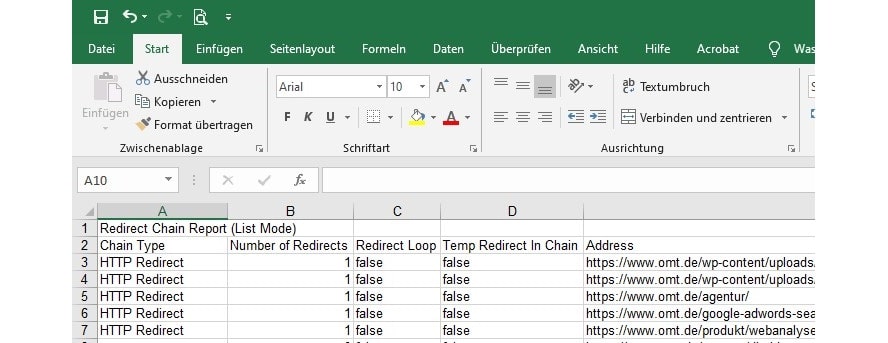
Abbildung 8: Report „Redirects & Canonical Chains“
Interne Links auf Redirects und Weiterleitungsketten auflösen
Auch ohne Relaunch kann überprüft werden, ob es interne Links gibt, die auf ein Redirect verweisen oder sogar über eine Kette von Weiterleitungen an die eigentliche Zielseite führen. Jede erneute Weiterleitung belastet den Server und verlängert letztendlich die Ladezeit der Seite. Bei Weiterleitungsketten entstehen auch Fehler, wie zum Beispiel Endlosschleifen oder das Weiterleitungsziel ist eine 404-Seite.
Um interne Links auf Redirects (interne Redirects) oder Weiterleitungsketten zu beheben wird der Crawl-Modus „Spider“ gestartet und der Crawler erneut angewiesen, Redirects zu folgen („Configuration“ > „Spider“, Reiter „Advanced“). Das anschließende Ergebnis im Reiter „Response Code“ anzeigen lassen und anschließen nach den Weiterleitungen (Redirection 3XX) filtern.
Nun kann jede einzelne URL im Detail analysiert und darauf überprüft werden, welche internen Links auf diese URL bestehen. Die Links können anschließend so angepasst werden, dass sie nicht auf den Redirect verlinken, sondern direkt zur eigentlichen Zielseite. Welche internen Links zur URL bestehen, listet der Screaming Frog im Reiter „Inlinks“ in der Fußzeile auf.
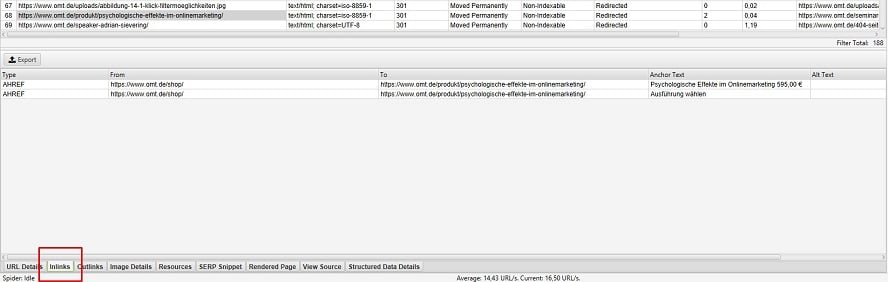
Abbildung 9: Interne Links zur ausgewählten URLs anzeigen lassen
Das Crawl-Ergebnis der internen Redirects lässt sich auch wieder als Excel-Liste exportieren („Bulk-Report“ > „Response Codes“ > „Redirection 3xx Inlinks“).
Um ein Redirect-Audit zu vervollständigen werden zudem noch die internen Weiterleitungsketten überprüft. Hierbei hilft erneut der Report „Redirect & Canonical Chains“.
Visualisierung der Webseitenstruktur und Fehler/Auffälligkeiten erkennen
Mit dem Update auf die Version 10.0 hat der Screaming Frog den neuen Menüpunkt „Visualisations“ erhalten. Hier verbergen sich vier interaktive Visualisierungen, welche die Seitenarchitektur darstellen. Sie sollen das Verständnis der Seite und der internen Linkstruktur und „Auffälligkeiten“ optisch verdeutlichen. Ergänzt wird der Menüpunkt um die Visualisierungen „Inlink Anchor Text Word Cloud“ und „Body Text Word Cloud“.
1. Unterschiede der interaktiven Visualisierungen:
Zwei Arten der interaktiven Visualisierungen stehen bereit: Crawl-Visualisierung und Verzeichnisbaum-Visualisierung. Beide können in zwei verschiedenen Formaten dargestellt werden, dem Baumdiagramm oder dem kraftgerichteten Diagramm.
- Crawl-Visualisierungen: „Crawl Tree Graph“ und „Force-Directed Crawl Diagram“
- Verzeichnisbaum-Visualisierungen: „Directory Tree Graph“ und „Force-Directed Directory Tree Diagram“
Alle Visualisierungen besitzen die gleichen Funktionen. Der Mouse-over eines Knotenpunktes zeigt eine Vielzahl an Informationen für die jeweilige URL an. Mit einem linken Mausklick werden alle nachfolgenden Verbindungen aus- oder auch wieder eingeblendet. Mit einem Rechtsklick bestehen weitere Funktionen. „Focus here“ ist bei größeren Seiten hilfreich, um den Überblick zu behalten oder sich auf einzelne Bereiche zu konzentrieren.
Jede der vier Visualisierungen lässt sich individuell in der Darstellung konfigurieren. Ein Klick auf das Zahnrad in der rechten oberen Ecke hält diese Einstellmöglichkeiten bereit. Der „i“-Button liefert die Informationen zu den einzelnen Farben der Knotenpunkte.
Auffällig sind in den Visualisierungen ggfs. die roten Knotenpunkte. Sie heben URLs hervor, welche nicht indexierbar sind oder einen Redirect besitzen. Nicht selten gibt es Gründe für nicht indexierbare Seiten. Die Darstellung ist jedoch hilfreich, um schnell Bereiche von Interesse zu identifizieren, die weiter untersucht werden müssen.
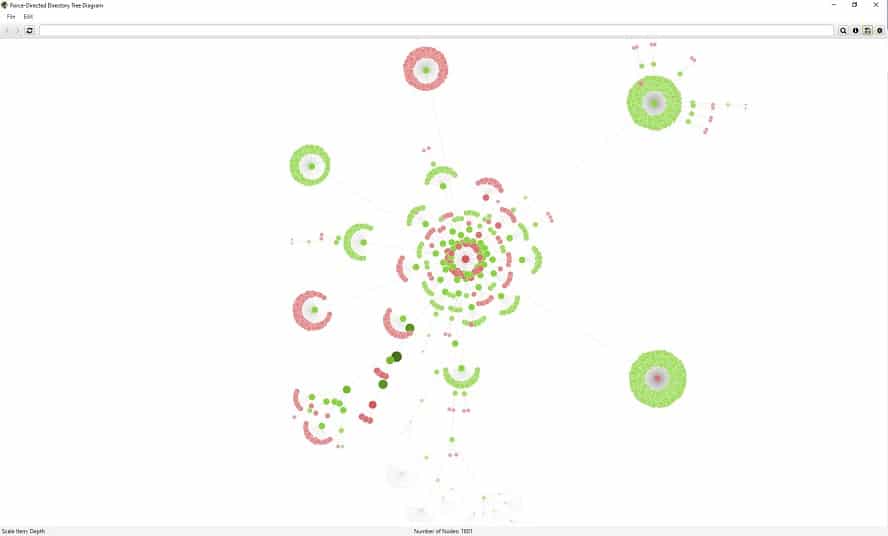
Abbildung 10: Force-Directed Directory Tree Diagram von omt.de
2. Die verschiedenen Arten der Visualisierungen im Überblick
Crawl-Visualisierungen:
Die Visualisierungen „Crawl Tree Graph“ und „Force-Directed Crawl Diagram“ gewähren einen Überblick darüber, wie der Screaming Frog die Website auf kürzestem Weg durchforstet hat. Angezeigt wird ein einzelner Pfad zu einer Seite von der Start-URL aus. Es wird nicht jeder interne Link angezeigt. Insbesondere bei größeren Webseiten wären die Visualisierungen dadurch unübersichtlich. Die Crawl-Visualisierungen sind bei der Analyse der Seitenarchitektur und der internen Verknüpfungen nützlich.
Verzeichnisbaum-Visualisierungen
Die Visualisierungen „Directory Tree Graph“ und „Force-Directed Directory Tree Diagram“ spiegeln die URL-Architektur einer Website. Die Knoten sind hierarchisch nach URL-Komponente und -Pfad organisiert. Sie geben nicht immer auflösende URLs wieder und die Linien zwischen den URLs repräsentieren den Verzeichnispfad. Dies macht die Visualisierung des Verzeichnisbaums bei der Analyse der URL-Struktur und der allgemeinen Informationsarchitektur einer Website nützlich.
Am Ende entscheidet der persönliche Geschmack, welcher Formattyp bei der weiteren Analyse der Crawl-Ergebnisse verwendet wird. Die Visualisierungen liefern jedoch nicht mehr Daten, als bereits in einem Crawl verfügbar sind.
Hilfereich dürften sie insbesondere für Web-Agenturen im Meeting mit dem Kunden sein. Visualisierungen haben eine Stärke: Sie helfen Perspektiven zu erzeugen, Ideen zu kommunizieren oder Muster aufzudecken, die in Tabellen nur schwer offenzulegen sind.
3. Ankertexte und Bodytext als Wortwolke
Alle Visualisierungen lassen sich entweder über das Menü aufrufen oder mit einem Rechtsklick auf eine URL in der Ergebnisliste der durchgeführten Analyse.
Vielmehr als nettes Gimmik dürften die beiden Visualisierungen „Inlink Anchor Text Word Cloud“ und „Body Text Word Cloud“ gesehen werden. Die Wortwolke für den Inlink-Ankertext enthält den gesamten internen Ankertext zu einer bestimmten URL und den Alternativtext eines Bildes mit Hyperlinks zu einer Seite. Die „Textkörper-Wortwolke“ enthält den gesamten Text im HTML-Textkörper einer Seite. Um diese Visualisierung anzuzeigen, muss die „Store HTML“ über die Spider-Konfiguration aktiviert sein.
Mein Fazit:
Der Screaming Frog SEO Spider hält definitiv eine Fülle an Features bereit. So ist einerseits eine schnelle und „oberflächliche“ Analyse einer Webseite möglich. Andererseits kann das Tool sehr gut genutzt werden, um viele individuelle SEO-Fragestellungen zu beantworten. So oder so: Der Screaming Frog ist ein sehr hilfreiches Tool, welches stetig weiterentwickelt wird und immer wieder mit beeindruckenden Neuerungen aufwartet. Mit ihm lässt sich bei der Onpage-Optimierung erfahrungsgemäß sehr viel Zeit sparen. Mein Tipp: Schaut euch den schreienden Frosch auf jeden Fall einmal an und probiert einige Funktionen aus. Ihr werdet begeistert sein.
Heiko Müller

Heiko Müller ist seit 2012 in der Agentur team digital GmbH im Bereich Online-Marketing tätig. Sein Schwerpunkt liegt in der Suchmaschinenoptimierung. Er berät sowohl Selbständige als auch kleinere Betriebe sowie international tätige Unternehmen. Für ihn ist wichtig, dass Webseiten in Hinblick auf Content, Struktur und Technik gut aufgestellt sind. Nur so können sie langfristig im Web und bei Usern erfolgreich sein.