
Wir haben täglich mit Entitäten zu tun: Treffen auf sie, fassen sie an oder interagieren gar mit ihnen. Fragt man dann aber eine x-beliebige Person, welche Entität sie denn kennt, bekommt man als Antwort meist kein Beispiel sondern nur ein ratloses Schulterzucken zu dem Begriff. Vielleicht liegt das daran, dass der Begriff der „Entität“ ursprünglich nicht aus der Informatik sondern aus der Philosophie stammt. Dort führte Platon das Wort „Ousia“ ein, was sich übersetzen lässt mit den Wörtern „Sein“, „Wesen“, „Seiendheit“ oder oft auch einfach nur „Substanz“.

Diese Substanz wiederum ist das eigentliche Wesen eines Dinges und macht es so zu einer Entität. Durch die Existenz der Ousia, kann ein Objekt die Eigenschaften der Eindeutigkeit und Identifizierbarkeit annehmen, was die Charakteristiken einer Entität sind. Damit ist eine Entität, insbesondere im Kontext der Informatik, nichts Anderes als ein eindeutig zu bestimmendes Objekt. Das kannst du oder ich sein, ein Ding wie dein Schreibtischstuhl an dem du sitzt oder der Bildschirm bzw. das Smartphone auf dem du diesen Text liest.
Diese kurze Einleitung macht es denke ich schon deutlich, warum sich bisher so wenige mit der Bedeutung von Entitäten beschäftigt haben. Obwohl sie uns täglich im Alltag ständig umgeben, sind sie in unserer Vorstellung dennoch wenig konkret greifbar.
Ähnlich verhält es sich auch im Online-Marketing und der Suchmaschinen. Schon im Jahr 2012 enthüllte Google den Knowledge Graph unter der bemerkenswerten Überschrift „Things, not strings“ 1. Keine Zeichenkette, sondern ein eindeutig, identifizierbares Objekt, also eine Entität, steht hinter den meisten Suchanfragen. Dieses neue Mantra, Entitäten über die eigentliche Suchanfrage zu stellen, zeigte sich aber im Jahr 2012 in den Suchergebnissen nur sehr selten. Vielmehr zogen die Entitäten eher schleichend in Googles Suchmaschine ein. Angefangen vom Knowledge Graph, weiter über das Hummingbird Update, bis in die Gegenwart, wo bei manchen Suchanfragen die dargestellten Entitäten die altbekannten „10 blue Links“ inzwischen dominieren und immer mehr verdrängen.
Höchste Zeit also sich mit dem Begriff Entität im Online Marketing-Kontext und hier insbesondere im Bereich der Suchmaschinenoptimierung zu widmen. Auf was es beim „Entity SEO“ ankommt und was man darunter überhaupt versteht, das erfährt man im nachfolgenden Beitrag.

Warum sind Entitäten so wichtig?
In der Philosophie gibt es Entitäten schon seit Ewigkeiten und auch in Teilbereichen der Informatik ist der Begriff alles andere als neu. Warum sind sie also nun „plötzlich“ so im Mittelpunkt von Suchmaschinen und der Optimierung?
Dafür genügt ein einfacher Vergleich von zwei identischen Suchanfragen, hier im Beispiel einmal aus dem Jahr 2000 und einmal aus dem Jahr 2019. Beides Mal wurde nach „Google“ gegoogelt, glücklicherweise ist das Internet dabei nicht explodiert, das Ergebnis könnte unterschiedlicher aber dennoch nicht ausfallen:
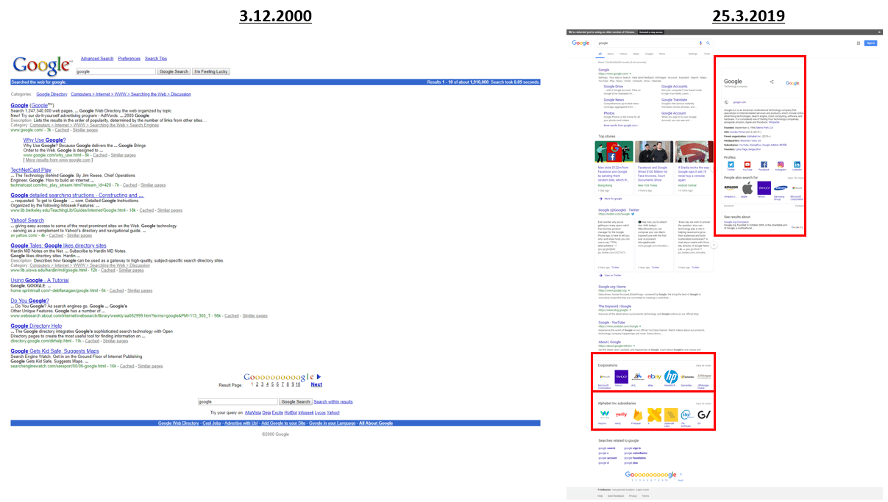
Während man im Jahr 2000 noch die bekannten und inzwischen schon legendären „ten blue links“ vorfindet, wurden diese im Jahr 2019 durch das „Top Stories“-Widget, Tweets von Twitter und eben auch zahlreichen Entitäten ersetzt bzw. angereichert. Auf der rechten Seite, rot umrahmt, sieht man das Ergebnis des Google Knowledge Graphs, eine semantische Datenbank von Google, in dem Entitäten mitsamt ihren Attributen und Beziehungen zu anderen Entitäten abgespeichert sind.
Jene Beziehungen werden auch unterhalb der Suchergebnisse (ebenfalls mit einer roten Markierung umrahmt) angezeigt. Dort zeigt Google nämliche Unternehmen, die mit Google kooperieren, sowie Tochtergesellschaften von Google an. Informationen aus dem Knowledge Graph werden damit nicht nur im sogenannten Knowledge Panel an der rechten Seite ausgespielt, sondern zum Beispiel auch in Karussells oder auch als direkt Antwort. Verwechselt werden darf dabei eine Antwort aus dem Knowledge Graph nicht mit den Informationen aus „Feature Snippets“ (hervorgehobenen Snippets), was einfach nur passende Informationen einer Website als Antwort auf eine Suchanfrage sind.
So spielt die Suchanfrage „Wer ist Googles CEO?“ ein Feature Snippet von Wikipedia aus, während die leicht umformulierte Suchanfrage „Wer ist der CEO von Google?“ eine Antwort aus dem Knowledge Graph liefert (Stand 18.08.2019):
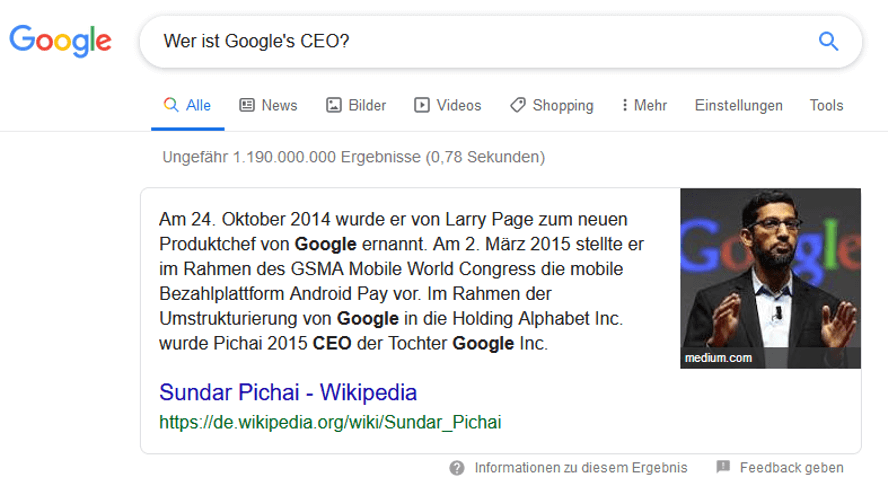
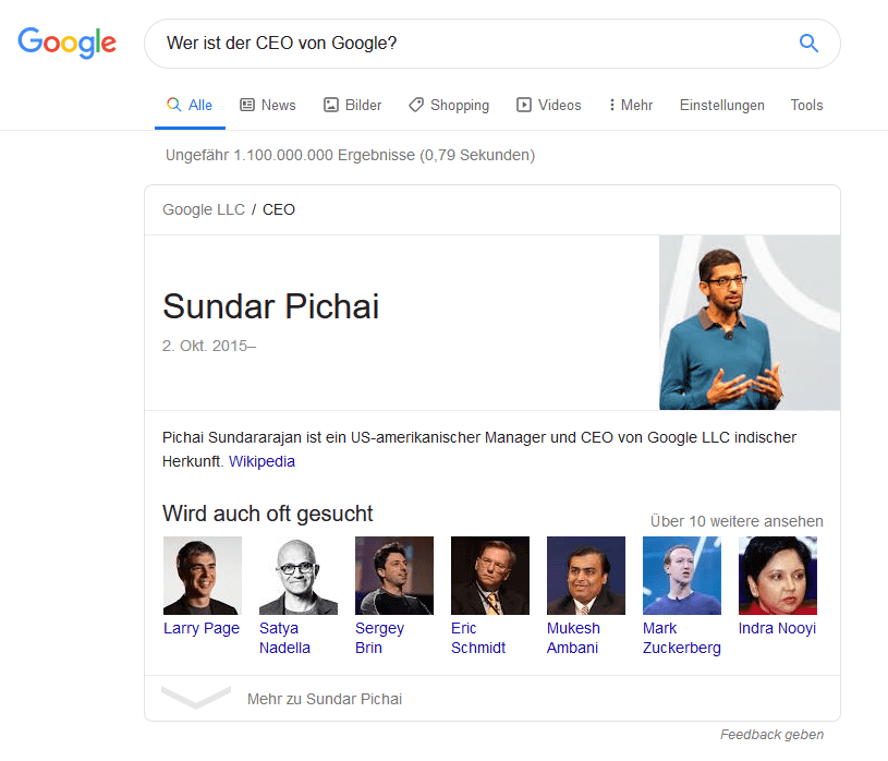
Die beiden Suchanfragen zeigen deutlich die Komplexität, mit der sich Google hinsichtlich den Entitäten konfrontiert sieht. Entitäten müssen nicht nur Google bekannt sein, sondern Google muss bei jeder Suchanfrage auch entscheiden, ob und welche Entität dahintersteckt.
Mit dem Hummingbird Update aus dem Jahr 2013, also rund einem Jahr nach dem Google den Knowledge Graph angekündigt hat, versucht Google diese Herausforderung auch algorithmisch im großen Stile zu lösen. 2 Spätestens mit dem Hummingbird Update wurde klar, dass Google den Weg zur semantischen Suche eingeschlagen hat und diesen auch konsequent verfolgen wird. Für Google ist der Knowledge Graph eine wichtige Investition in die Zukunft. Daten aus dem Graphen werden nämlich bei Weitem nicht nur für die Websuche genutzt, sondern dienen auch als Grundlage für weitere Dienste, wie zum Beispiel dem eigenen Kartendienst Google Maps, der mobilen Bilderkennungs-Anwendung Google Lens oder dem persönlichen Sprachassistenten Google Assistant. Warum der Knowledge Graph dabei so wichtig ist, machte Vice President Scott Huffman noch einmal auf der diesjährigen Entwicklerkonferenz Google I/O 2019 deutlich. So verkündete er dort3:
At Google, we approached this problem using our knowledge graph of things in the world and their relationships. […]“
President Scott Huffman, Google Vice President
Interessanterweise hat das Ergebnis der beiden oberen Suchanfragen zum CEO von Google, sich nicht einmal einen Monat später geändert. Seit Anfang September spielt Google bei mir auch bei der Suchanfrage „Wer ist Googles CEO?“ den Knowledge Graph-Eintrag und nicht mehr das Feature Snippet aus. Dies verdeutlicht noch einmal, dass die Erkennung von Entitäten einem stetigen Wandel unterliegt und sich Suchergebnisse von heute auf morgen jederzeit ändern können. Das muss auch in der Suchmaschinenoptimierung berücksichtigt werden.
Entitäten und deren Verarbeitung durch Google im unternehmenseigenen Knowledge Graph werden also weiter an Bedeutung zunehmen. Nachfolgend möchte ich deshalb im Detail vorstellen, was Entitäten genau sind, wie man selbst zur Entität wird und wie man eigene Entitäten in den Google Knowledge Graph aufnehmen lassen kann.
Was sind Entitäten?
Wie in der Einleitung schon hergeleitet wurden, sind Entitäten „eindeutig zu bestimmende Objekte“. Damit können Entitäten zum Beispiel Personen, Dinge, Bauwerke, Unternehmen, aber auch abstrakte Begriffe repräsentieren. Diese sehr weitgefasste Definition des Wortes Entität kann aber auch trügerisch sein. Insbesondere im SEO-Kontext darf man nun nämlich nicht der Verführung verfallen und jede Suchanfrage ab sofort mit einer Entität gleichsetzen. Eine Suchanfrage muss nicht immer explizit, sondern kann auch implizit eine Entität enthalten. Doch wie erkennt nun Google ob überhaupt und welche Entität in der Suchanfrage enthalten bzw. betroffen ist? Um diese Frage beantworten zu können und um noch besser zu verstehen, was denn nun eine Entität ist, lohnt sich einen Blick auf die Bestandteile einer Entität zu werfen.
Wer eine Ausbildung in der IT durchlaufen hat, der wird mit dem Wort Entität mit hoher Wahrscheinlichkeit das Entity-Relationship-Modell (kurz ER-Modell oder ERM) verbinden. Dieses eignet sich hervorragend, um die verschiedenen Bestandteile einer Entität einfach zu veranschaulichen. Das Entity-Relationship-Modell kommt aus der Datenmodellierung und wird dort beispielsweise im Bereich der Datenbanken häufig eingesetzt. Es ist die Darstellung eines Ausschnitts der realen Welt, in dem darin verschiedene Entitäten in Beziehung gesetzt werden.
Nachfolgend ein ganz einfaches Entity-Relationship-Modell:
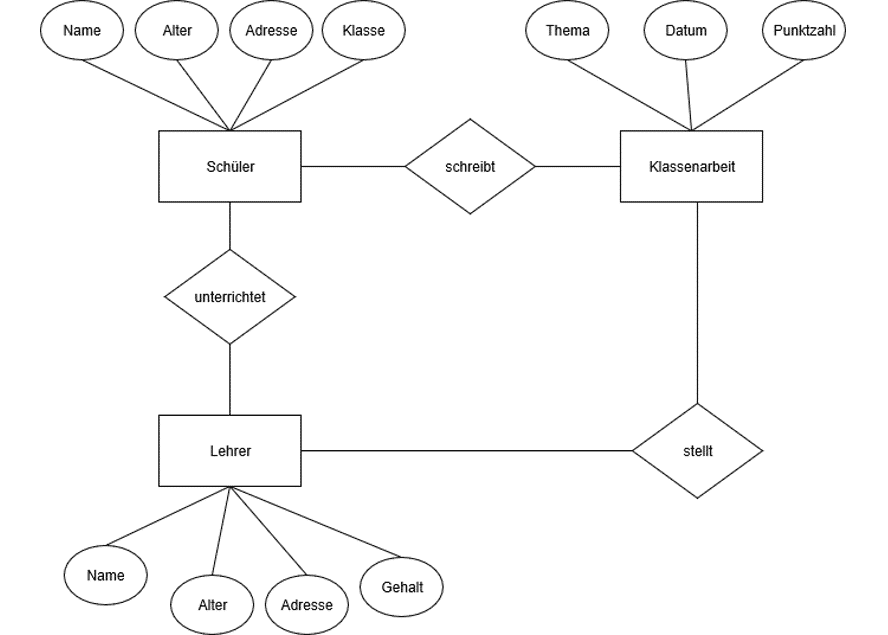
In diesem Entity-Relationship-Modell werden mehrere Entitäten dargestellt. Welche Entitäten sind das?
Falls Deine Antwort nun „Schüler“, „Lehrer“ und „Klassenarbeit“ ist, dann muss Ich Dich leider enttäuschen – dies sind keine Entitäten. Wie wir am Anfang gelernt haben, sind Entitäten eindeutig identifizierbare Objekte, in diesem Fall wäre eine Entität also beispielsweise der Schüler „Max, 10 Jahre alt, aus der Klasse 5B vom Holderweg 3“.
„Schüler“, „Lehrer“ und „Klassenarbeit“ wären in diesem Fall sogenannte Entitätstypen. Die Entitätstypen wiederum unterscheiden sich, einmal in den unterschiedlichen Attributen (im Diagramm durch Ellipsen dargestellt), die teilweise aber durchaus deckungsgleich zu andere Entitätstypen sein können, sowie den Beziehungen zu anderen Entitätstypen (im Diagramm durch Rauten dargestellt).
Und damit hätte man auch schon die wichtigsten Bestandteile einer Entität:
- Entitätstypen
- Beziehungen
- Attribute
Darüber hinaus benötigen Entitäten für die Speicherung und Verarbeitung in IT-Systemen zwei weitere Eigenschaften:
- Name
- Eindeutiger Identifikator
Die unterschiedlichen Bestandteile von Entitäten werden nachfolgend weiter im Detail vorgestellt.
Bestandteile einer Entität
Entitätstyp
Der Entitätstyp steht über der Entität und kann als eine Art abstrakte Klasse gesehen werden. Er bündelt verschiedene Entitäten mit den gleichen Attributen. Ein Entitätstyp ist dabei nicht absolut zu sehen, er kann wiederum selbst ein Typ sein. Zum Beispiel kann der Entitätstyp „Lehrer“, ein Subtyp des Entitätstyps „Beamter“ sein, der wiederum ein Subtyp des Entitätstyps „Mensch“ ist. In der Regel sind Entitätstypen hierarchisch aufgebaut. Dies wiederum erlaubt es, gewisse Schlüsse zu ziehen. Wenn wir beispielsweise wissen, dass der Entitätstyp „Lehrer“ ein Subtyp des Entitätstyps „Beamter“ ist und der Entitätstyp „Beamter“ wiederum ein Subtyp des Entitätstyps „Mensch“, dann wissen wir dadurch auch automatisch, dass ein „Lehrer“ dementsprechend auch ein „Mensch“ ist.
Zusammenhängenden Entitätstypen können selbst wiederum in sogenannte „Domains“ zusammengefasst werden. Die Domain „Filme“ könnte zum Beispiel die Entitätstypen „Schauspieler“, „Regisseur“ und „Drehort“ umfassen. 4 Die Entitäten innerhalb einer Domain können gewichtet werden, sodass sie einen unterschiedlichen Stellenwert in der Domain einnehmen. Würde die Domain „Filmgenres“ zum Beispiel die Entitätstypen „Romanzen“, „Actionfilme“ und „Dokumentation“ umfassen, dann könnte der Entitätstyp „Actionfilm“ wichtiger in der Domain „Filme“ sein als „Dokumentation“. Diese Gewichtung kann eine bedeutende Rolle spielen, da bei unklaren Suchanfragen, mit wenig bis keinen Kontext, die Maschine entscheiden muss, welche Entität nun inhaltlich bevorzugt dem Suchenden als Ergebnis angezeigt wird.
Beziehungen
Entitätstypen bzw. Entitäten werden erst so richtig interessant durch Beziehungen, denn nur dadurch lassen sich größere Zusammenhänge erschließen. Und erst durch diese Verknüpfung von Informationen lässt sich Wissen gewinnen, was letztendlich der größte Antrieb dafür ist, warum Entitäten beispielsweise für Suchmaschinen so interessant sind. Nur so gelingt die Transformation von der Such- zur Antwortmaschine.
Bei der sprachlichen Repräsentation von Beziehungen greift man auf Verben zurück, während Entitäten/Entitätstypen Subjektive sind. Ein Lehrer unterrichtet seine Schüler, und steht damit in einer Beziehung zu diesen.
Auch über Beziehungen von konkreten Entitäten lässt sich Wissen generieren. Wenn folgende Beziehungen gelten:
- Franz ist Vater von Hans
- Hans ist Vater von Max
dann könnten wir daraus schließen
- Franz ist Großvater von Max
Damit wüssten wir, nur durch die Information, wer von wem Vater ist, dass Franz und Max verwandt sind. Während man als Mensch diesen Zusammenhang relativ einfach erkennen kann, ist das für Maschinen erst einmal deutlich schwieriger. So muss ihnen das Wissen, dass ein Großvater ein Vater von einem Vater ist, erst einmal „beigebracht“ werden.
Exkurs: Ein System zur Wissensrepräsentierung besteht aus mehreren Komponenten, darunter der Terminologische Formalismus (die TBox) und der Assertionale Formalismus (die ABox). Während die TBox das terminologische Wissen enthält, also beispielsweise welche Klassen (Typen) es von Objekten gibt und welche Eigenschaften diese haben, findet man in der ABox das Wissen über eine konkrete Instanz (Entität), also ihre konkreten Eigenschaften und die Beziehungen zwischen ihnen.
- Beispiel aus der TBox: Großvater ist ein Vater von einem Vater
- Beispiel aus der ABox: Franz ist Vater von Hans, Hans ist Vater von Max
Durch die Information der TBox und den beiden Informationen aus der ABox kann ein System nun das Wissen generieren, dass Franz der Großvater von Max ist.
Zusammen ergeben die ABox und die TBox ein Knowledge Graph, wobei ein Knowledge Graph das Hauptaugenmerk auf die ABox hat. 5 Ob sich TBox und ABox zusammen in einem Graph befinden oder in separaten Graph bzw. in anderen Datenstrukturen, ist abhängig von der genauen Implementierung des Knowledge Graphs.
Attribute
Nicht immer sind die Fakten durch Entitätstyp und Beziehung so klar. Würde man sich beispielsweise nur den Entitätstyp „Käfer“ anschauen, wüsste man nicht, ob es sich jetzt um das Tier oder das Auto handelt. Sofort hingegen wird es klar, wenn man die zugehörigen Attribute vor sich hat. Das Attribut „Pferdestärke“ würde beispielsweise klar auf das Auto deuten. Andere Attribute, wie beispielsweise die „Farbe“, können hingegen noch nicht so klare Signale senden. Die Kombination und die Ausprägung der Attribute, sowie die Beziehungen, machen damit die Entität erst zur Entität.
Name
Über Namen sind Entitäten bekannt und können darüber angesprochen werden. Allerdings gibt es mit Namen folgende zwei Probleme
- Eine Entität kann unter unterschiedlichen Namen angesprochen werden, z.B. der bekannte Schauspieler Will Smith, auch unter den Namen Willard Carroll Smith Jr., Willard Carroll Smith, Willard Smith …
- Hinter einem Namen verbergen sich unterschiedliche Entitäten, z.B. gibt es in der englischsprachigen Wikipedia 11 verschiedene Will Smiths, darunter der Schauspieler, der Baseballspieler, die Kunstfigur in “Der Prinz von Bel-Air”, der Komiker etc.
Da Namen deshalb nicht einzigartig sind, braucht es neben dem Namen ein eindeutiger Identifikator. Für die Einordnung, welche Entität nun hinter dem Namen steckt, können wiederum die Attribute und Beziehungen helfen.
Eindeutiger Identifikator
Über einen eindeutigen Identifikator sind Entitäten innerhalb eines Knowledge Graphen einzigartig identifizierbar. Der wohl bekannteste eindeutige Identifikator im Web sind URLs. Von Büchern kennt man hingegen das Konzept in Form von ISBN-Nummern. Dieser eindeutiger Identifikator, unter dem die Entität angesprochen werden kann, gilt immer nur für das jeweilige System. Die gleiche Entität kann unter einem völlig anderen Identifikator in einem anderen System abgespeichert sein.
Definition: Entität
Nach dem wir nun so lange darüber geredet haben, was Entitäten überhaupt sind und welche Bestandteile diese besitzen, möchte ich anschließend gerne noch eine Definition aufführen, die meiner Meinung nach sehr zutreffend ist und alles bisher Aufgeführte in einen Satz vereint:
Definition: “An entity is a uniquely identifiable object or thing, characterized by its name(s), type(s), attributes, and relationships to other entities.”
Krisztian Balog, Entity-Oriented Search, S.3
Wie werden Entitäten organisiert?
Es wurde nun schon öfters der so genannte Knowledge Graph angesprochen und tatsächlich handelt es sich hierbei um eine Datenstruktur um Entitäten abzuspeichern und verwalten zu können. Generell könnten Entitäten aber auch in anderen Datenstrukturen, wie beispielsweise Tabellen, Datenbanken oder auch Listen abgespeichert werden. Graphen haben aber den Vorteil, dass sich hier Entitäten mit all ihren Bestanteilen ideal abbilden lassen. So sind die Knoten in einem Graphen die Entitäten oder Entitätstypen, sowie ihre jeweiligen Eigenschaften, während die Kanten, also die Verbindungen zwischen zwei Knoten, die Beziehungen darstellen. Graphen kann man jederzeit in Teilgraphen zerlegen, so könnte man generell auch einen Knowledge Graph konstruieren, der aus ganz vielen separaten Domain-Knowledge Graphen besteht.
Nachfolgend findet man eine beispielhafte Darstellung eines möglichen Teils eine Knowledge Graph aus dem Google Patent „Ranking search results based on entity metrics“6:
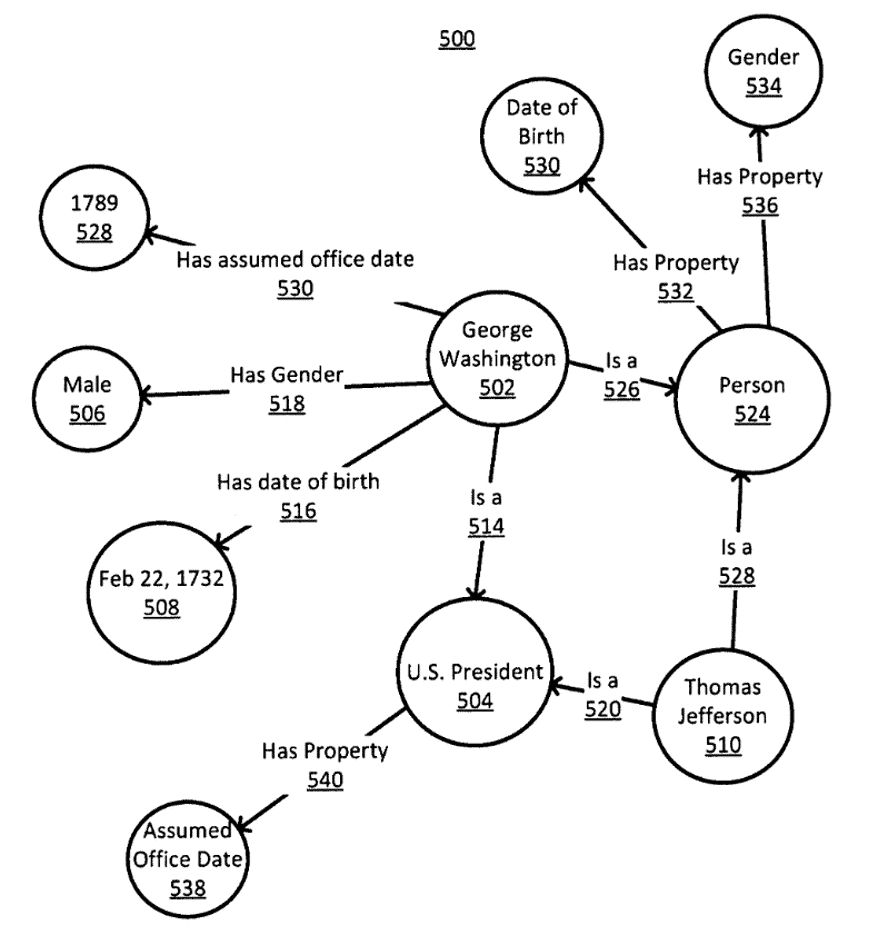
In der Darstellung sieht man beispielsweise die Entität „George Washington“ (wobei der Autor des Patents in diesem Fall von einer „Entity Reference“ spricht, da die wahre Entität die [inzwischen verstorbene] Person ja selbst ist). Diese Entität ist mit der Kante „is a“ dem Entitätstyp „Person“ zugeordnet. Der Entitätstyp „Person“ hat wiederum die beiden Eigenschaften „Date of Birth“ und „Gender“, sodass diese Beziehungen ein Teil des Schemas des Entitätstyps „Person“ festlegen.
Exkurs: Realisiert werden kann solch ein Knowledge Graph aus dem oberen Schaubild mit dem Resource Description Framework, kurz RDF. Modelliert werden die Aussagen im Graph dabei über sogenannte Tripels, in Form von Subjekt, Prädikat, Objekt. So lassen sich aus dem oberen Graph beispielsweise unter anderem folgende RDF-Triple extrahieren:
- George Washington has date of birth Feb 22, 1732
- George Washington has Gender Male
- Thomas Jefferson is a S. President
Diese RDF-Aussagen können nun mit verschiedenen Abfragesprachen, wie beispielsweise SPARQL, durchsucht und abgefragt werden.
RDF hat allerding ein paar Limitationen, so wäre das Triple „Äpfel essen Äpfel“ ebenfalls korrekt. Deshalb hat man mit RDFS oder auch OWL mächtigere Beschreibungssprachen, die mit einem größeren Vokabular, beispielsweise taxonomische Beziehungen oder Objektbeziehungen darstellen können.
RDF ist nur ein Konzept einer Graphendatenbank. Ein Knowledge Graph könnte ebenso als sogenannter Labeled-Property Graph (LPG) konstruiert werden. Beim LPG können im Vergleich zu RDF sowohl die Knoten als auch die Kanten Eigenschaften haben. Ein interessantes Video rund um den Unterschied zwischen RDF und LPG, sowie allgemein rund um Semantik in Graphen, findet man hier: https://youtu.be/OVweE–RJqM
Ein Knowledge Graph für einen abgesteckten Bereich kann man mit überschaubaren Aufwand jederzeit selbst erstellen. Umso mehr Entitäten, aus unterschiedlichen Domains der Graph aber beinhalten soll, umso schwieriger und aufwändiger wird es diesen aufzubauen und insbesondere die Qualität aufrechtzuerhalten. Es liegt dabei ein klassischer Zielkonflikt vor, zwischen den drei Zielen:
Dies ist auch der Grund, warum ein Knowledge Graph kein statisches Abbild der Wirklichkeit ist, sondern sich jederzeit verändern und erweitern kann. Die Entscheidung, einen möglichst allumfassenden Knowledge Graph aufzubauen, erfordert somit auch die entsprechenden Ressourcen dafür zur Verfügung zu haben.
Die wohl bekanntesten Knowledge Graphen betreiben Google mit dem Google Knowledge Graph und Microsoft mit dem Satori Knowledge Graph (basiert auf Microsofts Trinity Graph Engine und nutzt RDF) 7. Es gibt aber zahlreiche weitere Knowledge Graphen, viele davon sind auch unternehmensintern. Weitere Knowledge Graphen sind unter anderem beispielsweise:
- Diffbot Knowledge Graph: Nach eigenen Aussagen aktuell mit 10 Milliarden Entitäten und 1.000 Fakten, + 150 Millionen Entitäten/Monat (Stand Juni 2019) 8
- Microsoft Academic: Domain-spezifischer Knowledge-Graph mit akademischen Informationen (Wissenschaftler, Publikationen etc.)
- LinkedIn Knowledge Graph: Beinhaltet Mitglieder, Jobs, Unternehmen …
- Google Knowledge Vault: Kann auch als Google Knowledge Graph 2.0 gesehen werden, Extrahierung von Informationen erfolgt hier weitgehend automatisch, auch aus unstrukturierten Quellen.
- Wikidata: Stellt Strukturierte Informationen auf Basis der Wikipedia und darüber hinaus bereit
- Siri Knowledge Graph: Apples eigener Knowledge Graph für den Sprachassistenten Siri
- …
Hinweis: In der Wissenschaft ist man sich übrigens noch nicht ganz einig, was denn nun genau ein Knowledge Graph ist. 9 Insbesondere weil sich praktische Ansätze meistens wenig um akademische Definitionen scheren, findet man in der Realität die verschiedensten Ausprägungen von „Knowledge Graphen“.
Wichtig ist aber die Unterscheidung zwischen einem Knowledge Graph und einer Knowledge Base. Der Name sagt es schon, ein Knowledge Graph ist ein Graph, während eine Knowledge Base dies nicht zwangsläufig ist. Damit ist jeder Knowledge Graph auch eine Knowledge Base, bzw. nutzt eine Knowledge Base, anders herum muss eine Knowledge Base nicht zwangsläufig auch ein Knowledge Graph sein.
Da Google mit einem Marktanteil um die 90% hier in Deutschland den Suchmaschinenmarkt beherrscht, wollen wir uns nachfolgend nur noch auf den Google Knowledge Graph beschränken und schauen, wie man dort Entitäten platzieren kann und wie die Optimierung gelingt.
Googles Knowledge Graph
Die Grundlage für Googles Knowledge Graph ist Freebase, eine proprietäre Graphen-Datenbank, die Google durch die Übernahme von Metaweb im Jahr 2010 erwarb. Freebase wiederum wurde im Jahr 2015 zugunsten der freien Datenbank Wikidata geschlossen. Es überrascht deshalb nicht, dass Google seinen Knowledge Graph auch aus den ehemaligen Freebase-Informationen und den heutigen Wikidata-Daten speist. Nachfolgend findet man eine kleine Übersicht von weiteren Quellen, die Google für die Extrahierung von mögliche Entitäten für den Knowledge Graph heranzieht:
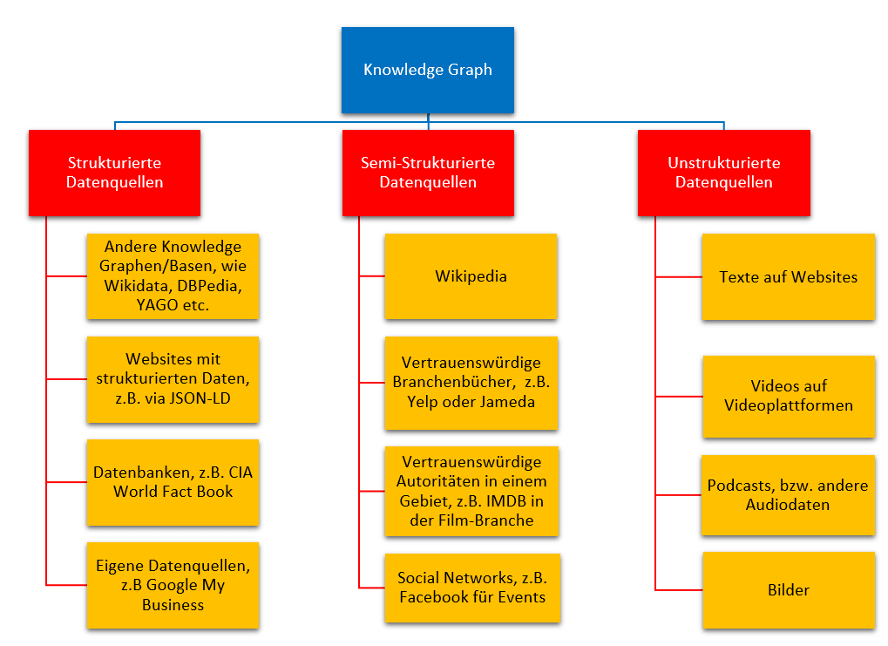
Wie kommt man in den Knowledge Graph?
Wie man in der oberen Abbildung sieht, speist sich der Knowledge Graph aus den verschiedensten Quellen. Möchte man also im Google Knowledge Graph mit der eigenen Entität repräsentiert sein, dann muss man sich vom Brunnen zur Quelle begeben.
Je nach Entität zieht Google verschiedene Quellen heran. Will ich beispielsweise mit meinem Event als Entität in Google Knowledge Graph aufgenommen und so bei Suchanfragen, wie beispielsweise „Stadt X Events“ ausgespielt werden, dann muss ich mein Event beispielsweise auf Facebook als Event eintragen oder auf spezielle Eventplattformen, wie Eventbrite, Evensi oder auch Krencky auffindbar sein. Oft sind auch lokale Plattformen die richtige Anlaufstelle. Ist man auf mehreren Plattformen vertreten, erhöht dies die Wahrscheinlichkeit von Google gefunden zu werden. In diesem Fall sollte man allerdings auch dringend auf Konsistenz bei den inhaltlichen Informationen auf den verschiedenen Plattformen achten.
Wer als Person oder Unternehmen als Entität in den Google Knowledge Graph aufgenommen werden will, der sollte über einen Eintrag in Wikidata nachdenken. Wikidata ist eine strukturierte Form von Wikipedia und zumindest aktuell kann man dort noch vergleichsweise einfach eigene Einträge erstellen. Der Königsweg wäre natürlich ein eigener Wikipedia-Eintrag, dies dürfte aber nur den wenigsten Einzelpersonen und auch den wenigsten Unternehmen durch die strengen Wikipedia-Richtlinien und Editoren möglich sein. Im Umkehrschluss bedeutet das aber wiederum, wer einen Wikipedia-Eintrag seinen Eigen nennen kann, der sollte diesen auch entsprechend pflegen und aktuell halten.
Per schema.org ausgezeichnete strukturierte Daten auf der eigenen Website sind und bleiben weiterhin wichtig für SEO, insbesondere, wenn Entitäten immer mehr in den Mittelpunkt rücken. Strukturierte Daten sind für Google Gold wert, schließlich helfen diese Daten durch ihre wohldefinierte Struktur beim Auslesen und Verarbeiten der Informationen. Um eine schema.org-Auszeichnung der wichtigsten Stellen auf der eigenen Website wird man dementsprechend in der Zukunft nur noch schwer Drumherum kommen. Ausgezeichnet werden können strukturierte Daten per RDFa, Mikrodaten oder JSON-LD. Google selbst empfiehlt die Auszeichnung via JSON-LD. Alles rund um strukturierte Daten findet man bei Google unter: https://developers.google.com/search/docs/guides/prototype
Wie kann man überprüfen, ob die eigene Entität schon im Knowledge Graph vorhanden ist?
Zwar gibt sich Google sehr bedeckt, wie der Knowledge Graph genau funktioniert, immerhin stellt der Suchmaschinenriesen aber eine öffentliche API bereit, über die man abfragen kann, welche Entitäten Google zu einem bestimmten Begriff im Graph abgespeichert hat.
Über den API-Explorer unter https://developers.google.com/apis-explorer/#p/kgsearch/v1/kgsearch.entities.search kann man jederzeit selbst den Knowledge Graph in kleinerem Umfang abfragen.
Einfach in das Query-Feld den Namen der Entität eingeben, die man überprüfen will und ggf. noch im Feld „Languages“ das Ganze mit „de“ auf Deutschland einschränken. Schon gibt Google aus, ob und was zur Eingabe im Graph abgespeichert ist.
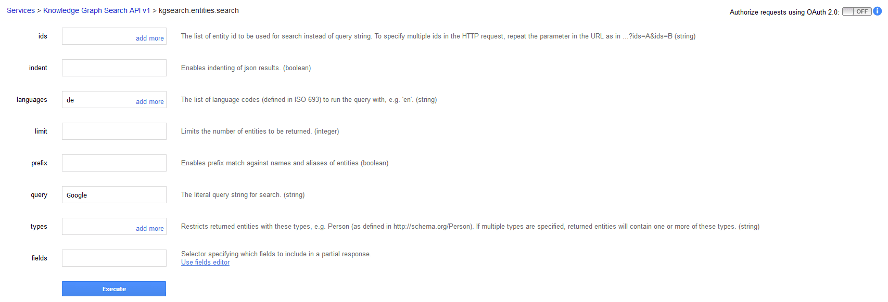
Ebenfalls kann man das Ergebnis auf Entitätstypen einschränken. Hier gibt Google einen ersten Hinweis, welche Entitätstypen aktuell im Knowledge Graph scheinbar besonders im Mittelpunkt stehen. Zwar schreibt Google selbst, dass die nachfolgenden Entitätstypen nur einige von möglichen Typen im Knowledge Graph sind, genannt werden aber explizit die Entitätstypen10:
- Book
- BookSeries
- EducationalOrganization
- Event
- GovernmentOrganization
- LocalBusiness
- Movie
- MovieSeries
- MusicAlbum
- MusicGroup
- MusicRecording
- Organization
- Periodical
- Person
- Place
- SportsTeam
- TVEpisode
- TVSeries
- VideoGame
- VideoGameSeries
- WebSite
Verlinkt wird bei jedem Entitätstyp jeweils auf die entsprechende Beschreibungsseite von schema.org. Wer sich also ebenfalls für die relevanten Attribute je Entitätstyp interessiert, der sollte auf jeden Fall einmal auf der jeweilige Schema.org-Seite vorbeischauen.
Die Antwort auf eine Abfrage des Knowledge Graph sieht man im Auszug im nachfolgenden Bild:
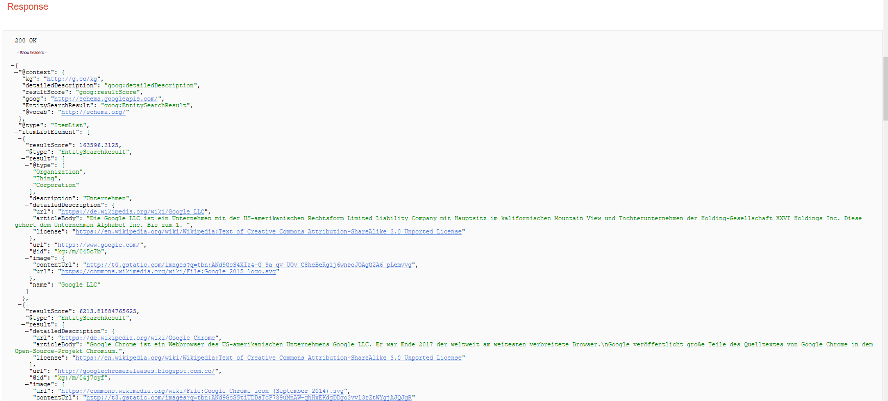
Wie man sieht, gibt die API eine JSON-LD Antwort zurück, in der die jeweiligen im Knowledge Graph enthaltenen Entitäten als einzelne Einträge dargestellt werden. Hier findet man je nach Entität unter anderem ihre ID, den Namen, den Typ, eine kurze und lange Beschreibung, ein Bild und auch eine zugehörige URL. Außerdem ist ein resultScore enthalten, der beschreibt, wie passend eine Entität auf die gewünschte Abfrage ist. Umso höher der Score, umso höher wird die entsprechende Entität auch in der Antwort gelistet. Hier wird es zukünftig sehr interessant sein herauszufinden, wie sich dieser Score zusammensetzt und wie man den Score der eigenen Entität beeinflussen und damit erhöhen kann.
Ausblick: Zukünftiges Entity-SEO
Dinge ändern sich, auch die Suchmaschinen und damit zwangsläufig auch die Suchmaschinenoptimierung. Sollten Entitäten weiterhin ihren Siegeszug fortsetzen und nicht nur die klassischen Suchergebnisse im Web, sondern auch andere Plattformen und Technologien, wie beispielsweise die Voice Search weiter besetzen, dann sollte man darauf nicht nur in der Informatik, sondern auch als Online-Marketing Verantwortlicher eingestellt sein. Durch bisher noch völlig unklaren Rankingkriterien, wie, wann und vor allem welche Entitäten in welcher Reihenfolge ausgespielt werden und auch in Hinblick auf Voice Search, wo Google im schlechtesten Fall nur noch eine einzige Entität ausgibt, sollte man sich dem Begriff frühzeitig intensiv widmen.
Schon bald könnte mit dem Entity-SEO dadurch eine weitere Teildisziplin der Suchmaschinenoptimierung entstehen. Entity-SEO könnte dann weitere Tätigkeitsfelder umfassen, wie beispielsweise die Erstellung und Schärfung des eigenen Entitäten- Profils, die Platzierung der eigenen Entität, sowie die Optimierung der Entität im Google Knowledge Graph. SEOs müsste dann noch mehr als heute, crossfunktionale Tätigkeiten, wie klassische PR oder auch Reputationsmanagement in einer Person vereinen oder in die Steuerung dieser unterschiedlichen Tätigkeitsfelder verstärkt übergehen.
Doch nicht nur für die eigene Entität im transaktionalen oder navigationalen Bereich könnte Entity-SEO eine Rolle spielen. Auch wenn man zukünftig mit den eigenen redaktionellen Inhalten im informativen Bereich für andere, fremde Entitäten weiterhin ranken möchte, könnte die entitäten-zentrierte Suchmaschinenoptimierung ein entscheidender Faktor sein.
In diesem Sinne SEOs: „Don’t think keywords! Think Entities.“
Die grundlegenden Informationen rund um die Optimierung deiner Entitäten sind Dir jetzt klar – mit uns findest Du die passende SEO Agentur, Google Agentur und oder Digitalagentur, die Dir hilft, Deine gesamte Strategie effektiv umzusetzen und Deine Ziele zu erreichen. Finde in unserem Agenturfinder die passende Agentur für Dein Unternehmen.
Quellen und Verweise
- 1 https://googleblog.blogspot.com/2012/05/introducing-knowledge-graph-things-not.html
- 2 https://search.googleblog.com/2013/09/fifteen-years-onand-were-just-getting.html
- 3 https://youtu.be/lyRPyRKHO8M?t=1768
- 4 https://patents.google.com/patent/WO2014089776A1/en, S. 9
- 5 Knowledge Graph Refinement: A Survey of Approaches and Evaluation Methods, S. 3, http://www.semantic-web-journal.net/content/knowledge-graph-refinement-survey-approaches-and-evaluation-methods
- 6 Ranking search results based on entity metrics, 61, https://patents.google.com/patent/WO2014089776A1/en
- 7 https://pdfs.semanticscholar.org/deef/13244a26756be076bc38a87ce3b86e909975.pdf
- 8 https://youtu.be/nwqyjoVBrmg?t=640
- 9 https://www.researchgate.net/profile/Wolfram_Woess/publication/323316736_Towards_a_Definition_of_Knowledge_Graphs/links/5a8d6e8f0f7e9b27c5b4b1c3/Towards-a-Definition-of-Knowledge-Graphs.pdf
- 10 https://developers.google.com/knowledge-graph/
Weitere Informationen zum Thema
- Kostenloses eBook von Krisztian Balog: Entity-Oriented Search: https://eos-book.org/
- Artikelreihe über semantische Suchmaschinenoptimierung von Olaf Kopp: https://www.sem-deutschland.de/blog/semantische-seo-entitaeten/
- Artikelreihe „The Entity & Language Series” von Cindy Krum: https://mobilemoxie.com/blog/entity-first-indexing-mobile-first-crawling-1-of-5/
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen






Super Blogpost. Bringt die SEO-Welt mit der Knowledge-Graph-Welt sehr verständlich zusammen. Man merkt der Autor kennt sich aus 🙂