
Wenn es um das Crawling und die Indexierung von Seiten geht, wirst Du sicher schon einmal vom Canonical Tag oder auch kanonischem Tag bzw. kanonischen URLs gehört haben.
Vereinfacht gesagt, dient der Canonical Tag dazu Suchmaschinen zu zeigen, auf welcher URL sich der originale Content (Hauptversion) befindet. Dadurch kann man aktiv Duplicate Content entgegenwirken. Beim Setzen von Canonical Tags kann man jedoch so einiges falsch machen.
Welchen Sinn und Zweck der Canonical Tag hat, wie Du ihn richtig einsetzt und welche häufigen Fehler Du unbedingt vermeiden solltest, erfährst Du in diesem Artikel.

Was ist ein Canonical Tag?
Der Canonical Tag ist ein HTML-Tag, der von Webmastern verwendet wird, um anzugeben, welche URL als die “Haupt”- oder “Original”-URL für eine bestimmte Seite betrachtet werden soll. Der Canonical Tag wird in der Regel in der Kopfzeile einer Webseite platziert und sieht in etwa so aus:
<link rel=”canonical” href=”https://example.com/original-page/” />
Welchen Sinn hat ein Canonical Tag?
Der Canonical Tag wird verwendet, um Duplikate, sprich gleiche Inhalte von Webseiten zu vermeiden, die möglicherweise durch unterschiedliche URLs verursacht werden. Zum Beispiel könnten mehrere URLs einer Seite verfügbar sein, wenn die Seite über verschiedene Domainnamen aufgerufen werden kann oder wenn es unterschiedliche Wege gibt, um auf dieselbe Seite zu gelangen (z.B. über einen Link mit oder ohne “www” am Anfang).
Ohne den Canonical Tag könnten Suchmaschinen diese URLs als separate Seiten behandeln und sie möglicherweise doppelt in den Suchergebnissen anzeigen, was die Nutzererfahrung beeinträchtigen und die Suchmaschinenoptimierung (SEO) der Seite negativ beeinflussen kann.
Mit der Verwendung des Canonical Tags kann angegeben werden, welche URL als die “offizielle” oder “vorzugsweise” verwendete URL für eine Seite betrachtet werden soll, und somit vermeiden, dass Suchmaschinen diese Seite und dessen Inhalte mehrfach indizieren.
Der Canonical Tag kann auch verwendet werden, um Suchmaschinen darüber zu informieren, dass eine Seite Teil einer größeren Sammlung von Seiten ist, wie zum Beispiel einer Kategorie- oder Produktdetailseite. In diesem Fall sollte der Canonical Tag auf die “Haupt”-URL der Sammlung verweisen, anstatt auf die individuelle Seite.
So setzt Du einen Canonical Tag
Entscheide zunächst welche URL das „Original“ bzw. die „Hauptversion“ werden soll und gebe den anderen URLs mit gleichem Inhalt (Duplikat) einen Canonical Link Tag. Es gibt verschiedene Möglichkeiten, einen Canonical Link Tag zu setzen.
In den meisten Fällen wird ein Link mit Verweis zur „Original URL“ in den <head> des HTML-Codes eingefügt, dieser sieht wie folgt aus:
<link rel=”canonical” href=”https://www.test.de/xyz ”/>
Hat die kanonische Seite eine mobile Version, musst Du einen rel=”alternate”-link hinzufügen, der auf die mobile Version der Seite verweist:
<link rel=”alternate” media=”only screen and (max-width: 640px)”
href=” https://www.test.de/xyz “>
Du kannst auch hreflang-Tags oder andere Weiterleitungen hinzufügen, die für die Seite geeignet sind.
Es gibt noch die Möglichkeit einen HTTP-Header rel=”canonical” zu nutzen, allerdings unterstützt Google diese Methode derzeit nur für Websuchergebnisse.
Falls Du WordPress nutzt, kannst Du Canonical Tags ganz einfach mit Plugins wie Yoast setzen.
Achtung: Gerade bei größeren Seiten kann es zeitsparend sein, den Canonical Tag lediglich in der Sitemap anzugeben. Jedoch, so Google: „Wir garantieren nicht, dass wir die Sitemap-URLs als kanonisch einstufen, aber Sitemaps erleichtern die Festlegung kanonischer Seiten für eine große Website.“ (Quelle: developers.google.com)
Die Methode 301-Weiterleitung eignet sich nur für deaktivierte Seiten.
Best Practices: So wird der Canonical Tag richtig verwendet
Google selbst empfiehlt für den Einsatz des Canonicals folgende Best Practice:
- Weitgehende Übereinstimmung
Ein Großteil der Information und Inhalte der Duplikatsseite sollte auf der kanonischen Version enthalten sein. - Vorgehen bei der Überprüfung
Um dies zu überprüfen, empfiehlt Google sich vorzustellen, man verstünde die Sprache der Seite nicht und die kanonische und die duplizierte Seite nebeneinanderzulegen und zu überprüfen, ob ein sehr großer Teil der Wörter auf beiden Seiten identisch ist. - Canonical Tag wird von Google ignoriert
Wenn die Seite lediglich thematisch ähnlich sind, aber nicht wortwörtlich übereinstimmen, kann der Canonical Tag von den Suchmaschinen ignoriert werden! - Existenz der Zielseite überprüfen
Überprüfe stets, dass das Ziel des Canonical Tags auch tatsächlich existiert. - “Noindex” Status überprüfen
Stelle sicher, dass die kanonische URL keinen “noindex” Robots Meta-Tag im Quellcode enthält. - Ist die kanonische URL diejenige, die auch in den Suchergebnissen erscheinen soll (anstatt der duplizierten URL)
- Platzierung des Tags an verschiedenen Stellen möglich
Der Canonical Tag kann sich sowohl im <head> Element der Webseite als auch im HTTP-Antwort-Header befinden. - Nur einen Canonical Tag pro URL definieren
Definiere nur EINEN Canonical Tag. Sollten im Quellcode mehrere vorhanden sein, werden sämtliche Canonical Tags ignoriert!
(Quelle: developers.google.com)
Canonical Tag und hreflang gemeinsam verwenden
Es ist möglich, den Canonical Tag und den hreflang-Tag gemeinsam auf einer URL zu verwenden. Der Canonical Tag wird in der Regel im Head-Bereich der Seite platziert, während der hreflang-Tag als Link-Element im Head-Bereich der Seite oder als HTTP-Header in der Antwort der Seite platziert wird.
Hier ist ein Beispiel für den Einsatz beider Tags auf einer Seite:
<head>
<link rel=”canonical” href=”https://www.example.com/de/seite1″>
<link rel=”alternate” hreflang=”de” href=”https://www.example.com/de/seite1″>
<link rel=”alternate” hreflang=”en” href=”https://www.example.com/en/page1″>
</head>
Im obigen Beispiel wird der Canonical Tag verwendet, um anzugeben, dass die URL “https://www.example.com/de/seite1” als die Haupt-URL für die Seite betrachtet werden soll, während der hreflang-Link angeben, dass es Versionen der Seite für Nutzer in Deutschland (“de”) und Englisch (“en”) gibt.

Es ist wichtig zu beachten, dass der Canonical Tag und der hreflang-Link unterschiedliche Zwecke haben und daher auch unterschiedlich verwendet werden. Der Canonical Tag wird verwendet, um Duplicate Content zu vermeiden und Suchmaschinen mitzuteilen, welche Version einer Seite bevorzugt werden sollte, während der hreflang-Link verwendet wird, um Suchmaschinen mitzuteilen, welche Seite für welche Nutzer:innen am relevantesten ist. Es ist daher wichtig, dass Du sicherstellst, dass beide Tags korrekt verwendet werden und keine widersprüchlichen Informationen enthalten.
Die 7 häufigsten Fehler mit dem Canonical Tag und wie Du diese vermeidest
Fehler 1: rel=canonical auf die erste Seite einer Paginierung
Dieser Fehler wird leider immer wieder bei paginierten Seiten gemacht. Man möchte natürlich, dass die Kategorieseiten gut ranken und so kommen viele SEOs auf die Idee mithilfe des Canonical Tags die paginierten Seiten 2,3,4 etc. auf die erste Seite zu verweisen, um dort die maximale Kraft zu bündeln.
Stelle Dir vor, Du hast beispielsweise URLs wie:
- example.com/kategoriexyz/
- example.com/kategoriexyz/?seite=2
- example.com/kategoriexyz/?seite=3
und so weiter.
Hier nun den “rel=canonical” von Seite 2 und den Folgenden auf die erste Seite zeigen zu lassen, ist kein korrekter Einsatz des Canonicals, da dies keine Duplikate der ersten Seite sind!
In diesem Beispiel sorgt der Canonical Tag sogar dafür, dass der gesamte Inhalt dieser Seiten nicht indexiert wird und auch die dort enthaltenen Links auf weitere Produkte, Inhalte, etc. nicht von der Suchmaschine gewertet werden. Manchmal ignoriert Google jedoch falsche Angaben im Canonical Tag, wenn sich die Seiten unterscheiden. (Quelle: developers.google.com)
So geht es richtig:
Im Falle von paginierten Seiten sollte man entweder den Canonical Tag auf eine URL zeigen lassen, auf der alle Produkte gelistet sind (“View-All-Page”) oder den Canonical Tag selbstreferenzierend auf die jeweilige Seite. Den “rel-prev” und “rel-next” Link beachtet Google nicht mehr (Quelle: searchengineland.com) und Seite 2 und Folgende auf “Noindex” zu setzen, ist leider auch keine Lösung mehr, seitdem Google Long-Term-Noindex-Seiten wie Nofollow-Seiten behandelt (Quelle: seroundtable.com).

Fehler 2: Absolute URLs versehentlich als relative URLs verwendet
Der Canonical Tag akzeptiert grundsätzlich sowohl relative als auch absolute URLs. Hierbei kann es jedoch zu falscher Verwendung kommen, insbesondere wenn die Seite mit einem “<base>-Tag” und relativen URLs arbeitet, denn dann weiß die Suchmaschine nicht, auf welche Domain sich die Kanonisierung bezieht.
wird fehlerhaft interpretiert, je nachdem in welchem Verzeichnis sich die Seite gerade befindet als:
http://example.com/example.com/cupcake.html oder gar http://example.com/verzeichnis-der-aktuellen-seite/example.com/cupcake.html
Idealerweise wird die gesamte URL angegeben:
oder die absolute URL ohne Domain angegeben:
Denn auch bei Verwendung einer relativen URL wie:
kann es in einem Unterverzeichnis dazu kommen, dass die URL falsch zusammengesetzt wird.
Fehler 3: Versehentliche Mehrfachverwendung des Canonical Tags
Gerade bei selbst entwickelten Content Management– oder Shop-Systemen kann es passieren, dass mehrere Regeln greifen und der Canonical Tag dann doppelt oder gar noch häufiger ausgegeben wird.
Ist dies der Fall ignoriert Google sämtliche Anweisungen und behandelt die Seite wie eine URL ohne Canonical Tag!
Fehler 4: Canonical Tag um unterschiedliche Seiten zusammen zu fassen
Insbesondere seit das Page-Rank-Sculpting mit internen “Nofollow”-Links nicht mehr funktioniert, versuchen viele SEOs die Kraft von Seiten, die zwar sehr viele Links erhalten, aber eigentlich gar nicht ranken sollen (Beispiel Impressum, AGB, Datenschutz) mittels Canonical Tag auf eine gewünschte SEO Landingpage zu verschieben. Leider ist diese Mühe zumeist vergeben, da die Seiten einfach zu unterschiedlich sind und außerdem die Gefahr besteht, dass Google sämtliche Canonical Tags der Domain ignoriert.
Fehler 5: Der Canonical Tag im <body> der HTML-Seite
Der Canonical Tag gehört in den “<head>-Bereich” des HTML-Dokuments. Findet die Suchmaschine einen Canonical Tag im “<body>” wird dieser schlicht ignoriert. Zu groß wäre hierbei die Gefahr, durch eingeschleusten Code von außen die Kraft der URL abziehen zu können.
Fehler 6: Keinen “Rel-Canonical” bei URL-Parametern
Bei vielen Seiten ist standardmäßig gar kein Canonical Tag implementiert. Der Bedarf wird häufig nicht gesehen, doch auch wenn man nicht bewusst mehrere Seiten zusammenführen möchte, sollte der Canonical Tag stets auf die kanonische URL zeigen, also auf die URL unter der die jeweilige Seite erreichbar ist. Der Grund hierfür sind URL-Parameter, die sich häufig durch Tracking oder andere Gründe in die URL einschleichen und schnell für eine Mehrfacherreichbarkeit sorgen und im schlimmsten Falle Duplicate Content verursachen.
Selbst SEOs machen diesen Fehler, wie man bei einer Abfrage von SEO mit “inurl:utm_source” leicht herausfinden kann:
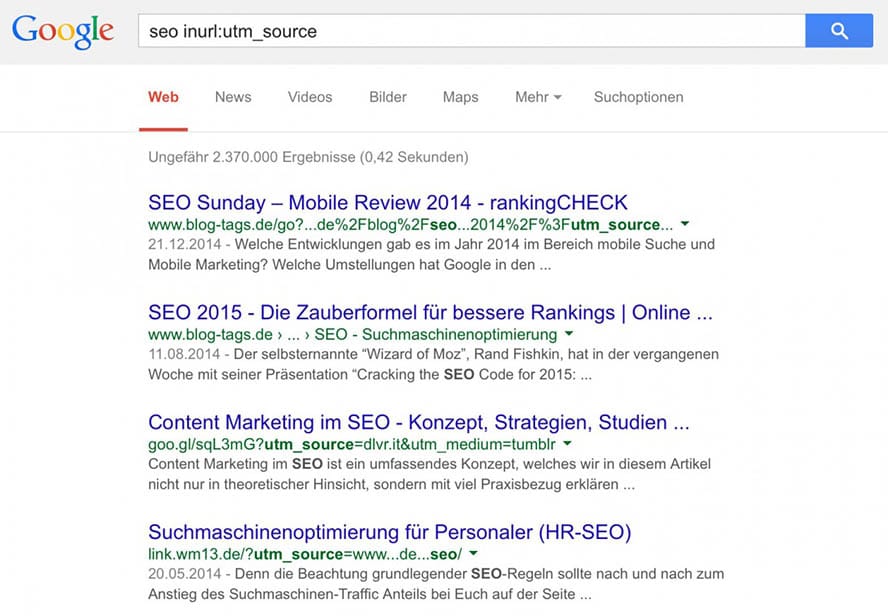
Fehler 7: Keinen Canonical-Tag in der mobilen Webseite
Mobile Webseiten werden immer wichtiger, soviel ist klar. Oft wird die Webseite für mobile Endgeräte unter einer anderen URL ausgeliefert, z.b. “m.example.com” oder Ähnliches.
Wie bereits im Textabschnitt um Setzen des Canonical Tags erwähnt, ist es wichtig die mobile Variante nicht nur von der Normalen aus mittels “Rel-Alternate” anzugeben:
Sondern eben auch auf der mobilen Webseite dann die jeweilige URL der Desktop Version im Canonical-Tag anzugeben:
Dies empfiehlt Google auch explizit im Leitfaden für mobile Webseiten (Quelle: developers.google.com)
Fazit
Ich hoffe, dass ich a) erklären konnte, was ein Canonical Tag ist und b) insbesondere mit diesem Artikel einige Fehlannahmen beseitigen konnte und Ihr nun den Canonical Tag korrekt einsetzen könnt, um Duplicate Content zu vermeiden.
Falls Euch noch häufige Fehler einfallen oder Ihr Fragen zu konkreten Anwendungsfällen des Canonical Tags habt, freue ich mich sehr über einen Kommentar!
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





Guter Artikel. Bin darüber gestolpert, da ich gerade gestern meine selbstgestrickte “Uralt-Webseite” aktualisiert habe und nach Einreichen der Sitemap in der Google Search Console unter “Abdeckung” gelesen habe, dass eine Seite wegen “Duplicatcontent” nicht indexiert wurde. Und das ist leider gerade die HAUPT- bzw. Startseite. Der HJinweis der Meldung lautet: “Duplikat – eingereichte URL nicht als kanonisch festgelegt” Nun, die Startseite lautet einerseits auf www………….index.html (das ist auch diejenige welche “beanstandet” wurde. Ansonst wurde in der Sitemap auch die normale url der Startseite hochgeladen. Diese wurde akzeptiert. Wohin gehört nun der Canonical-Tag , in die “index-seite” oder in die normale… Weiterlesen »
Die .index.html und die domain ohne was dahinter http://www……….de/ sind wohl identisch, wenn ich deine Ausführungen korrekt interpretiere. Daher würde ich Dir vorschlagen, den Canonical Tag auf der index.html auf http://www….de/ zu stellen. Dann haste dort die Startseite und kein Duplikat mehr unter index.html
Danke bestens für den Tip. Ja, du hast recht. Beide Seiten sind intentisch. Also Canonical-Tag in die “Index-Seite”.
In der Zwischenzeit habe ich den Canonical auf der indek-Seite hochgeladen und dieser wird im Header auch korrekt angezeigt. Leider aber ist die index-Seite nach wie vor einzeln aufrufbar. Benötigt das eine gewisse Zeit bis der Canonical greift (Beispiel bis zum nächsten Google-Crawling) oder müsste die Index-Seite nach den Upload des Canonical sofort weg sein?
Interessanter Artikel. Ich habe gerade überlegt wie ich das auf einer Affiliate Seite löse auf der pro Kategorie 50 Artikel angezeigt werden. Google mag ja verständlicherweise keine Linklisten. Wenn jeweils der Titel, das Bild und ein “zum Shop” Button verlinkt sind macht das pro Seite 150 externe “nofollow” Links. Ich denke mir mal das kann nicht gut sein, muss aber sagen das Ranking ist dafür wirklich nicht schlecht. Jetzt mache ich gerade einen Test bei dem ich zuerst nur die ersten 5 Ergebnisse ausgebe (url: https://www.domain.de/shop?marke=test&modell=test&sent=1) danach einen “mehr anzeigen…” Balken mit Link zu (url: https://www.domain.de/shop?marke=test&modell=test&sent=2) wo dann die kompletten… Weiterlesen »
Vielen Dank für den tollen Artikel! Ein Aspekt des canoncial-Links, der mich gerade beschäftigt, sind Produktseiten in einem Online-Shop, der sehr viele Varianten-Artikel anbietet. Eine Variante kann beispielsweise das gleiche T-Shirt in rot oder weiß sein. Jede Variante ist einzigartig und ist über eine eigene URL aufrufbar. Trotzdem unterscheidet sich der Content nur minimal. Allerdings hat jede Variante eine eigene Artikelnummer und sollte deshalb auch selbst ranken bzw. über Google gefunden werden können. Empfiehlt es sich trotzdem, mit einem canonical Link von allen Varianten z.B. auf die günstigste Variante zu verweisen? Oder würde Google einen nicht vorhanden canonical-Link in diesem… Weiterlesen »
Das ist immer ein Grenzfall, den man je nach Anzahl und Bedeutung der Farbvarianten individuell entscheiden muss. Falls man nicht jede Farbvariante zum ranken bringen kann oder will, sollte idealerweise die Farbe über einen gesperrten Parameter ausgewählt werden, so dass der Googlebot die Varianten garnicht lesen kann. Zumindest sollte der Canonical hier, trotz kleiner Abweichungen greifen, zur Sicherheit würde ich alle, bis auf eine Farbe auf noindex setzen oder einen Artikel mit mehreren Farben, die zur Wahl stehen in Title etc. in den Index nehmen und die einzelnen Farben nicht. ODER eben jede Farbe ausoptimieren und separat zum ranken bringen.… Weiterlesen »
Hallo Kai, Entweder stehe ich gerade etwas auf dem Schlauch, oder aber es ist etwas unglücklich formuliert, wie eine korrekte Pagination ausgezeichnet sein sollte. Einerseits schreibst Du, bzw. ist die Google Vorgabe: “Ein Großteil der Information der Duplikatsseite sollte auf der kanonischen Version enthalten sein.” “Wenn die Seite lediglich thematisch ähnlich sind, aber nicht wortwörtlich übereinstimmen, kann der Canonical-Tag von den Suchmaschinen ignoriert werden!” Andererseits aber: “Im Falle von paginierten Seiten, sollte man entweder den Canonical-Tag auf eine URL zeigen lassen, auf der alle Produkte gelistet ist …” Das wären dann in Deinem Lösungsvorschlag doch komplett unterschiedliche Inhalte? Einmal eine… Weiterlesen »
Hallo Frank, zu deinen Fragen: Im ersten Punkt ist mein Artikel in der Tat etwas unglücklich formuliert. Laut Google sollte die URL exakt übereinstimmen, oder wie im Beispiel mit der View-All-Page den Inhalt vollständig enthalten. So wären hier Seiten 1 bis X auf eine gemeinsame View-All-Page kanonisiert, die alle Produkte enthält, die auf den paginierten Seiten aufgeteilt zu sehen sind und damit stimmen die Inhalte ebenfalls überein! Mit dem Thema Long-Term-Noindex sprichst Du einen guten Punkt an: Mittlerweile lasse ich das noindex auf den Seiten 2 und folgenden ebenfalls weg, da Google hier mehrfach nachgelegt und diese Vorgehensweise als die… Weiterlesen »
Hallo Kai, ja, mittlerweile habe ich das noindex auf den gepagten Seiten auch bei allen Kunden raus genommen und stattdessen bei allen gepagten URLs ein Canonical auf sich selbst. Finde ich auch blödsinnig, aber irgend ein kleinstes Übel muss man ja wählen 😉 Bei den kanonischen Verweisen der einzelnen gepagten URLs auf eine View-All zweifle ich etwas daran, dass Google das tatsächlich so korrekt interpretiert, speziell bei einer größeren Anzahl gepagter URLs. Da auch in der GSC immer wieder verwirrende eigene Google-Theorien zu “vermeintlich korrekten” kanonischen URLs auftauchen, traue ich deren Fähigkeiten nicht so weit wie ich gucken kann. Und… Weiterlesen »
Ich habe unter Fehler 3 Ursprung meines Problems gefunden, jedoch keine Lösung… Wie schaffe ich die kryptischen Seiten (bspw. “8/?et_blog”) von meiner Website gelöscht? Gefühlt sind sie genauso viele wie meine Beiträge