Wie erhälts du Insights zu einem Blackbox-Algorithmus wie die von Google? Ganz klar und fast schon ein No-Brainer: Wir tracken das Verhalten, denn die größte Spur hinterlässt Google mit seinen Crawlern auf deiner Webseite. Jeder einzelne Hit, jeder einzelne Fehler und jede noch so kleine Anomalie und Verhaltensmuster wirst du in deinen Logfiles extrahieren können. Das Beste an Logfiles ist: Erstens müsst ihr nichts dafür zahlen und die Insights daraus gleichen einer unendlichen SEO Goldgrube. Ich bin der leidenschaftlichen Meinung, dass Logfiles das Leben und den Alltag eines jeden SEOs erheblich erleichtern. Und wenn du der Meinung bist, du kannst technisch nichts mehr optimieren, dann musst du definitiv in deine Logfiles schauen.

Was sind Logfiles und wie sehen die aus? Zur Auffrischung erkläre ich das in ein paar kurzen Sätzen:
Webserver speichern jeden einzelnen Request die bearbeitet werden, unabhängig von dem eingesetzten Webserver. Sei es der Apache, Nginx oder aber auch Cloud-Anbieter wie beispielsweise der Salesforce Cloud Commerce, jede Software erstellt quasi einen Protokoll seiner arbeit. Diese werden dann gespeichert und irgendwo abgelegt.
Eine Zeile sieht dann beispielsweise folgendermaßen aus:
66.249.76.56 – – [08/Sep/2017:09:23:08 +0200] “GET http://www.yourdomain.com/skin/frontend/default/fonts/OpenSans-Light.woff HTTP/1.1″ 200 19984 “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
Das wiederholt sich dann pro verarbeitete Request so weiter und scheint fast unendlich zu sein.
Wichtige Komponenten sind dann zum Beispiel folgende Daten
– IP-Adresse
– Zeitstempel
– Angeforderte Ressource
– HTTP Statuscode
– Größe der Ressource
– User-Agent String
Damit wären wir auch bei den ersten drei Insights:
- Logfiles sind bei größeren Seiten sehr sehr groß. Bei unseren Setups verarbeiten wir Monatlich Terabytes an Daten, was natürlich sehr herausfordernd ist. Wie wir was lösen, kommt gleich.
- Logfiles enthalten personenbezogene Daten. Das ist die Alarmglocke für jeden Datenschützer. Heißt für euch: es muss ein Punkt in AGBs, Privacy Policy etc. eingepflegt werden. Siehe als Beispiel (https://corporate.aboutyou.de/en/privacy-policy). Viel wichtiger ist die Weiterverarbeitung der Daten. Am Besten ist es ihr anonymisiert die Daten, in dem ihr die letzten 16-Bits der IP-Adresse nullt. Beispielsweise wird dann aus der IP 66.249.76.56 ( welche von Google ist) die IP-Adresse 66.249.0.0. Somit ist die IP-Adresse „verallgemeinert“ und nicht auf eine Person zurückzuführen und trotzdem kriegt ihr die Zuordnung zu Google-Crawlern. Diese beginnen im Großteil mit 66.249.
- Logzeilen und einzelne Metriken können erweitern/manipuliert werden. Apache beispielsweise kann Informationen die Verarbeitungszeiten wie Time to first byte oder time to serve request mitloggen. Das hilft ungemein bei der Erkennung von schlechten Backend-Timings und unperformanten Requests. Oder aber auch bei der Erkennung von abgerauchten Servern.
Nun kommen wir zu den Insights direkt aus den Cases.
Wie bereits erwähnt, können Logfiles sehr groß werden. Damit du ein Gefühl hast ein Beispiel für eine Domain in einem unserer Cases:

Die Setups um so einen Datenvolumen zu handlen variieren jedoch nach Kundenanforderungen. Wir arbeiten mit drei unterschiedlichen Setups.
- Ein selbstgemanagtes Cluster vom ELK-Stack, sei es auf eigener Hardware oder auf der AWS oder GCP. Das bietet die höchstmöglichste Flexibilität und Individualität, was auch am günstigsten ist. Nachteil ist der DevOps-Aufwand und die Wartung eines hochdynamischen Clusters.
- Eine Serverless-Architektur auf GCP, wo wir die Rohdaten auf Cloud Storage speichern, mit Dataflow verarbeiten und anreichern, innerhalb von BigQuery ablegen und schlussendlich mit Data Studio visualisieren. Dieses Setup ist am einfachsten zu Warten und flexibel genug.
- Das Nutzen des Elastic Cloud Services, welches alles unter einer UI anbietet, jedoch auch am teuersten von allem ist. Kunden/Anwender ohne DevOps-Erfahrung oder Ressourcen sind hier am Besten aufgehoben.
Du musst dich nicht festnageln auf eines der oben genannten Setups. Das kann beliebig erweitert oder verändert werden. Jedoch hat sich das für unseren Alltag bewährt.
Kommen wir zu den tatsächlichen SEO Insights. Was bringt die Analyse der Logdaten für einen Mehrwert in meiner operativen SEO Tätigkeit? Legitime Frage und hier folgt die Antwort, was wir aus bisher 4-5 Milliarden Serverhits im Jahr an wertvollen Insights extrahiert haben. Unsere Cases sind ausschließlich aus eCommerce-Cases im Enterprise-Umfeld.
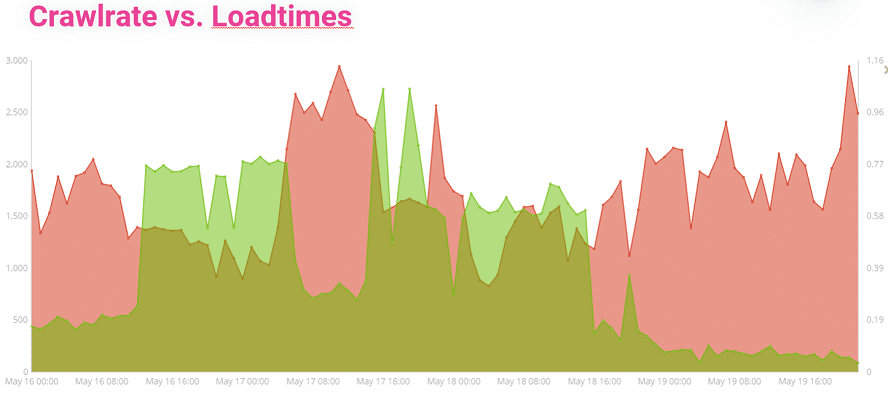
Crawlrate vs. Loadtimes?
Die Linie in rot steht für die Anzahl der Hits durch Google-Crawler. Die rote Linie zeigt die Ladezeiten an. Hier wird deutlich wie sensibel Google auf Veränderungen der Ladezeiten und vor allem auf hohe Ladezeiten reagiert. Kaum steigt die Ladezeit, verabschieden sich Crawler höflich und crawlen vermutlich bei der Konkurrenz weiter. Wer so eine Ansicht nicht monitort, dem Fehlt das Wissen zu seiner eigenen Infrastruktur.
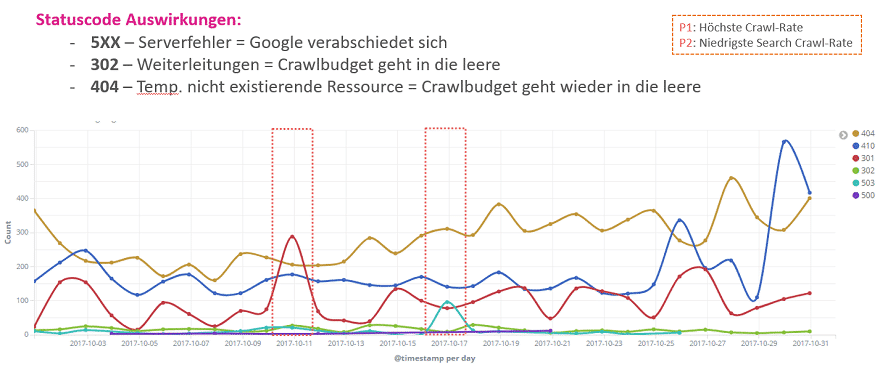
Auswirkungen von Statuscodes
Jeder SEO kennt die Statuscodes auswendig, doch die Auswirkungen auf das Crawlverhalten sind meistens unbekannt bzw. wird kaum beachtet. Um zu sehen wie Google mit einzelnen Statuscodes umgeht, haben wir uns kritische Statuscodes analysiert. 500er Serverfehler(siehe Abbildung P2) sind für Google ein umissverständliches Signal, dass er aufhören soll zu crawlen. Selbst bei 10-20 Hits halbiert sich Crawlrate. Bei Weiterleitungen jeglicher Art steigert Google die Crawlrate nahezu auf das Doppelte(höchste Crawlrate im Analysezeitraum – siehe P2). Ähnliches findet statt, wenn viele 404er ausgespielt werden. Hier werden aber auch umliegende Seiten und Unter/Oberkategorien gecrawlt, um zu sehen, ob die Inhalte im Index noch aktuell sind.
Effizienz von Ressourcen / Caching-Strategien
40KB für ein Font sind nicht viel richtig? Schonmal die Zahlen für einen gesamten Monat analysiert für einen eCommerce-Player der auf 15 Ländern aktiv ist? Ich fasse es zusammen: knapp 100GB an erzeugter Bandbreite in einem Monat und unfassbar viele Requests die der Webserver unnötig verarbeitet.
Grund dafür sind fehleden Caching-Guidelines. Es sind keine sinnvolle Ablaufzeiten definiert. Mechanismen wie ETags oder Cache-Control werden häufig vernachlässigt. Wenn du dann einen gesamtheitlichen Blick auf die Logfiles wirfst, siehst du die tatsächlichen Auswirkungen. Insbesondere bei JS und CSS-Ressourcen zählt jeder Byte.
In diesem Fall haben wir die Fonts(die übrigens komplett rausgeworfen worden sind, da kein visueller Unterschied für den User) rausgekickt. JS und CSS Ressourcen wurden mit Brotli um ca. 17% reduziert.
Killer-Argumente für die Feedmanager, SEA Manager und Social Media Guys
SEOs haben schon immer die Fehler der Marketingleute ausgebügelt. Mit Logfiles könnt ihr die direkten Verantwortlichen finden und die Zahlen auf die entsprechende Nase binden. Oder höflich darauf hinweisen.

Der Vorteil von Logfiles sind, dass auch die Crawler von Google Ads / Bing Ads sichtbar sind. Check mal die Crawlabdeckung der SEA-Feeds. Wir haben entdeckt, dass 28% der URLs innerhalb von drei Monaten, nicht gecrawlt. Grund war eine Änderung der URL Struktur, wo die SEA Manager vergessen hatten, die Kampagnen-URLs zu aktualisieren. Ähnliches bei der Affiliate Kampagne: 3.5 Millionen weitergeleitete URLs im Monat aufgrund der Nutzung von veralteten URLs. Stell dir die unnötige Serverlast vor. Anstatt 70 Backend-Servern würden dann 50 Server auch ausreichen. Vorallem bei Social Media sind dann noch ewig-alte URLs verlinkt, die in die leere Laufen oder über 4 Hops weiterleiten.
In einem Case haben wir entdeckt, wie sich Sucheinsprungs-URLs für User/Suchmaschinen auswirken. Diese URLs, welche für Google Feeds gedacht waren, hatten 3-4fach langsamere Backend-Werte. Fazit: Sucheinsprünge werden nicht mehr für Ads benutzt.
Crawlt Google bis zur letzten Seite meiner Kategorieseiten?
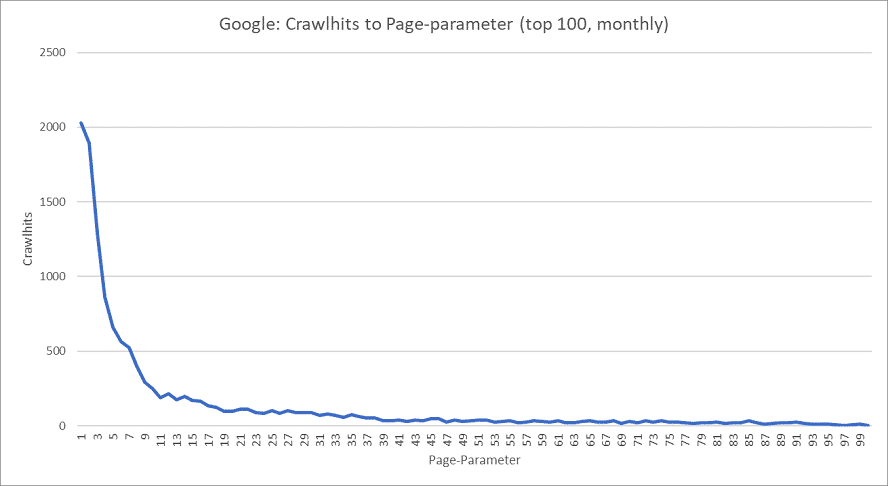
Die Frage ist, brauchst du überhaupt 456 Paginierungsseiten. Google crawlte in unserem Fall effektiv nur bis Seite 40. Die Crawlhits danach waren verschwindend gering. Du lernst durch die Logfiles wie Google überhaupt deine Seite wahrnimmt und mit dieser interagiert.
In einer anderen Auswertung haben wir die Relevanz der Hauptnavigationspunkte für Google gemessen. Dort wurde dann sichtbar, wie Google mit der Navigation umgeht, was das für unsere interne Verlinkung bedeutet und wie wir die Reihenfolge optimieren könnten.
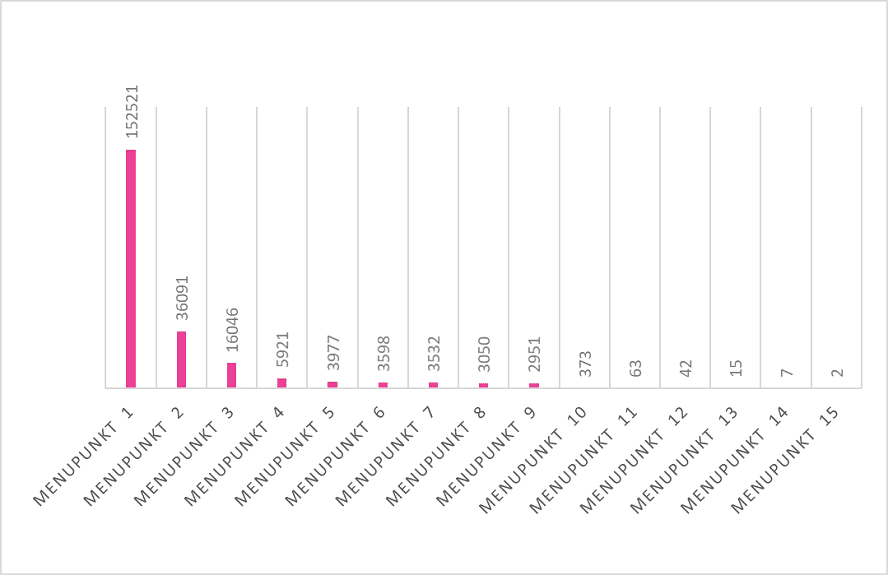
Der erste Navigationspunkt wurde bis zu fünfmal mehr aufgerufen als der Zweite und das zieht sich konsequent linear durch.
Hall of Fail: Vertrauen ist scheiße, Kontrolle hilft Allen
Den krönenden Abschluss möchte mit einem ganz besonderen Fund machen. Denn ein Entwickler hat es tatsächlich geschafft jeder Seite eine Passwortvalidierung unterzujubeln. Genau, auf jeder Seite des Shops wird das Passwort, was in ein Formular getippt wird validiert. Nicht nur, dass es unnützer Code auf jeder Seite ist. Die Validierung fand clientseitig statt – alle Passwörter die vermeintlich Schwach waren oder häufig verwendet wurden, waren in einer 400KB Datei eingebunden. So wurde das Passwort quasi mit der Weltliteratur abgeglichen und dass auf jeder einzelnen URL der Seite. In Zahlen: 200GB Gesamttraffic, 10GB an Googlecrawler. Mehr als sieben Sekunden schnellere Time-to-Interactive wurden erzielt, wobei sich die Seitengröße um 30% reduziert hat. Wie gesagt: Vertrauen ist keine gute Sache, zumindest nicht bei Entwicklern.
Logfile-Analysen und Monitorings sind die treuen Begleiter eines jeden SEOs. Wir führen fast keine Relaunches/Launches, keine SEO-Strategie und keine Maßnahmen ohne sie durch. Ohne Logfiles fehlt uns das Fundament einer datengetriebenen SEO-Strategie. Alles was Entwickler, IT, Frontend oder Backend jemals unter den Teppich gekehrt haben, werden durch Logfiles zu Tage getragen. Nur wer seine Logfiles tiefgehend analysiert und beobachtet kann eine effiziente und saubere Infrastruktur für Suchmaschinen und User anbieten.
Wir haben für unsere Kunden mehr als 4 Milliarden Server-Hits analysiert und haben etliche Insights, Quick-Wins, Fails und einen einzigartigen Einblick in das Crawlverhalten von Google-Crawlern gewonnen. Insbesondere große Infrastrukturen profitierten von den gewonnen Insights, da wir jeden einzelnen Hit kritisch ausgewertet haben und bis ins Detail gegangen sind.
Für mehr Cases und Insights hat das OMT-Team ein Webinar vorbereitet, wo wir noch mehr Insights haben, wo du Fragen stellen kannst oder auch deine Erfahrungen teilen kannst.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen