
Daten scheinen allgegenwärtig zu sein. Manche sehen in ihnen sogar das Öl des 21. Jahrhunderts: Den Treibstoff unserer modernen Existenz, der es Unternehmen ermöglicht, ihre Geschäfte zu führen und hocheffizient auf Kunden zuzugehen. An dieser Stelle allerdings hört die Analogie zum Öl auch schon auf. So bedarf es zwar großer Anstrengung, das „schwarze Gold“ aus der Erde zu gewinnen, wenn es sich aber erst einmal sicher in den Fässern befindet, ist die größte Arbeit getan und das Öl leicht zu verwenden. Konträr verhält es sich bei den Daten: Sie sind bei den eigenen Kunden oder durch den Ankauf von Dritten relativ einfach zu erheben. Die Daten dann aber richtig einzusetzen, um seine Kunden auf eine persönlichere Art und Weise anzusprechen und einen Wettbewerbsvorteil gegenüber der Konkurrenz zu erlangen, ist hingegen eine echte Herausforderung. Denn Daten lassen sich auf ganz unterschiedliche Art und Weise interpretieren und bergen daher auch ein extrem hohes Potenzial für falsche Schlussfolgerungen. Die Gründe dafür sind vielfältig. Einer der wichtigsten, auf den wir in diesem Text näher eingehen werden, ist das Versäumnis, die Daten so miteinander zu verknüpfen, dass sie die richtigen Erkenntnisse liefern.
Was meinen wir überhaupt, wenn wir von Daten sprechen?
Bevor wir tiefer in die Bedeutung der Datenkonnektivität eintauchen, lasst uns zunächst klären, was unter Daten überhaupt zu verstehen ist. Wenn wir in der Welt des Online-Marketings, genauer gesagt des programmatischen Marketings, über Daten sprechen, meinen wir damit vor allem Verbraucherdaten. Informationen über das Verbraucherverhalten werden verwendet, um zu entscheiden, wie Produkte oder Dienstleistungen an bestimmte Zielgruppen am besten vermarktet werden können. Diese Daten können auf viele verschiedene Arten gesammelt werden. So können Website-Betreiber ihre Nutzer beispielsweise zum Ausfüllen einer Umfrage oder einer Produktbewertung auffordern. Oder sie nutzen Codeschnipsel, auch als Pixel oder Tags bekannt, um mehr über das Verhalten ihrer Kunden zu erfahren.
Absolut entscheidend ist es aber, sich bewusst zu machen, dass Daten nicht gleich Daten sind. So unterscheiden wir in unserer Branche zwischen First-Party, Second-Party und Third-Partydaten. First-Party-Daten sind Informationen, die Du direkt und unmittelbar bei Deinen Kunden einsammelst, wenn diese sich zum Beispiel für Deinen Newsletter anmelden oder Du generell das Browsingverhalten deiner Kunden auf der Website verfolgst. Informationen werden zu Second-Party Daten, wenn eine andere Firma sie sammelt und dann direkt an Dich weiterverkauft. Die letzte Art von Informationen sind die Third-Party-Daten: Dabei handelt es sich um solche Daten, die von einem Aggregator, einer dritten Partei, gesammelt werden, der diese Daten dann wiederum als Datenpakete weiterverkauft.
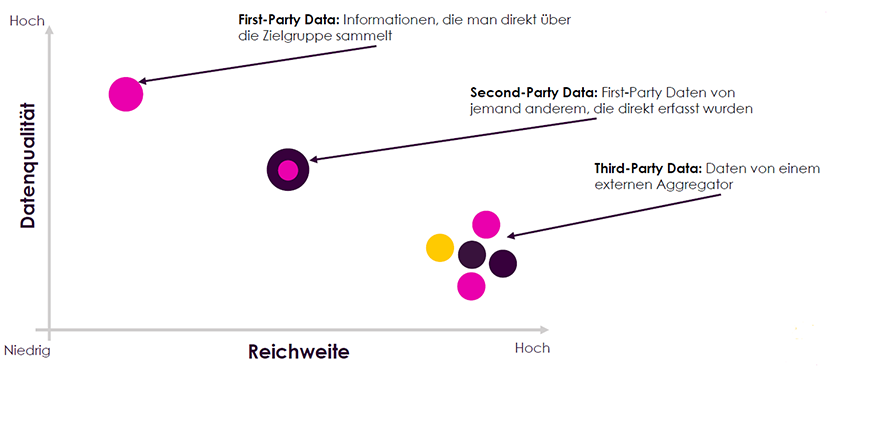
Verhältnis von Datenqualität und Reichweite in Bezug auf First- Second- und Third-Party Data.
Unendliche Datenmengen
Während das weltweite Ölvorkommen begrenzt ist, ist die Menge an Daten schier unendlich und wächst mit einer atemberaubenden Geschwindigkeit sogar immer weiter an. Jüngsten Schätzungen zufolge werden im Internet jeden Tag mehr als 2,5 Trillionen Bytes Daten erzeugt. Wenn wir diese gigantische Menge in je 10 Gigabyte große Blöcke zerlegen würden, kämen wir jeden Tag auf 93.000 solcher Blöcke. Zum Vergleich, um die Relationen zu verdeutlichen: Ein 10-Gigabyte-Block entspricht etwa 341.333 E-Mails, 682 Youtube-Videos, 170 Stunden in Google Maps oder 105 gestreamten Episoden auf Netflix. Und die Geschwindigkeit, in der wir immer mehr Daten produzieren, nimmt exponentiell zu: Etwa neunzig Prozent der weltweiten Daten wurden erst in den letzten zwei Jahren erzeugt.
Die größte Herausforderung für Vermarkter besteht daher in der sinnvollen Selektion und Nutzung dieser Daten und darin, die richtigen Erkenntnisse daraus zu gewinnen. Dies geht auch aus einer Umfrage unter Vermarktern hervor, die MiQ im Mai 2018 durchgeführt hat. 93 Prozent der Befragten gaben darin an, dass der Einsatz von Data Science und Datenanalysen zur Gewinnung tieferer Einblicke in ihre Marketing-Initiativen “sehr wichtig” oder zumindest “etwas wichtig” ist. Die Antworten fielen länder-, berufs- und branchenübergreifend ähnlich aus. Gleichzeitig gaben 43 Prozent an, dass ihre größte Herausforderung darin besteht, die tatsächlichen geschäftlichen Auswirkungen der Datennutzung und -analyse für ihr Unternehmen zu messen. 39 Prozent klagten über Schwierigkeiten bei der Interpretation und sinnvollen Nutzung der Daten. All diese Probleme führen dazu, dass nur 13 Prozent der befragten Vermarkter tatsächlich das Gefühl hatten, mit ihren derzeitigen Lösungen die Geschäftsergebnisse wirksam voranzutreiben.
Daten miteinander verbinden
Wie also können Vermarkter ihr Setup verbessern und Voraussetzungen schaffen, die ihnen wirklich einen Wettbewerbsvorteil gegenüber der Konkurrenz einbringen? Um diese Frage zu beantworten, müssen wir uns genauer ansehen, welche Arten von Daten wir miteinander verbinden können. Dies sind die gängigsten Datenquellen, die im Programmatic Advertising verwendet werden:
- Customer Relationship Management (CRM): Unabhängig davon, ob sie in einer Software, wie zum Beispiel Salesforce, oder auf andere Weise verarbeitet werden, sammeln die meisten Unternehmen Daten über bestehende Kunden und deren Verhalten.
- Adserver: Daten von Anzeigenservern bieten eine Zusammenfassung aller digitalen Aktivitäten und sind daher ebenfalls eine sehr wichtige Datenquelle.
- Pixel: Die oben erwähnten Daten aus Pixeln oder Tags geben Auskunft über das Nutzerverhalten auf Deiner Website.
- Web Analytics: Dies sind Informationen, die sich aus der Analyse Deiner Website ergeben, zum Beispiel mithilfe von Tools wie Google Analytics. Diese Daten enthalten wichtige Informationen über Visits auf der Website oder die Zeit, die die Nutzer auf einer Domain verbringen.
- Custom Client Integrationen: Diese Art von Daten fällt häufig unter den Tisch, ist aber nicht minder interessant: Denn sie geben Auskunft über externe Faktoren, die das Verbraucherverhalten beeinflussen. Damit kann das Wetter gemeint sein, bestimmte Aktionen von Konkurrenten oder Trends in den sozialen Medien. Grundsätzlich kann jeder Faktor, der das Verhalten Ihrer Kunden beeinflussen könnte, als wertvoller Datenpunkt dienen und herangezogen werden.
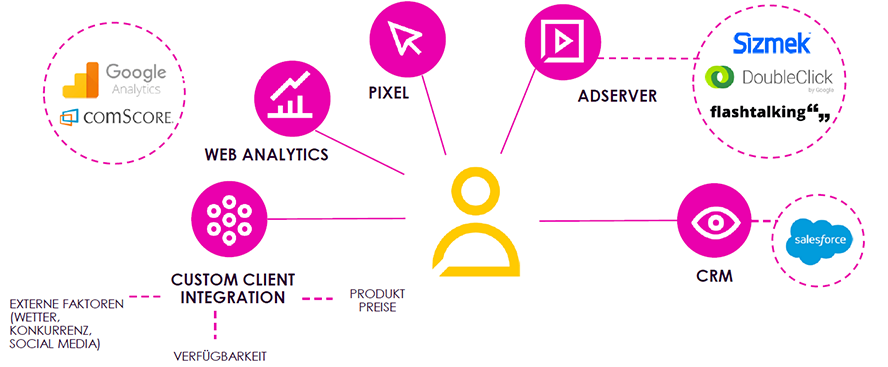
Diese Datenquellen können miteinander verbunden werden.
Die Datenanalyse als fließender Prozess
Wie aber schafft man es, diese verschiedenen Datentypen erfolgreich miteinander zu verbinden? Mit einer guten Infrastruktur, die aus drei wesentlichen Punkten besteht: Der Datenaufnahme, der Datenstrukturierung sowie der Analyse bzw. Aktivierung. Der Stellenwert dieser drei Aspekte lässt sich am besten mit einer Analogie zur Nahrungsmittelproduktion erklären. Die Datenaufnahme bedeutet zunächst, die Daten zu ernten und zu einem Verteilerzentrum zu transportieren. So stellst Du, genau wie bei Nahrungsmitteln, sicher, dass die Daten nicht verderben und im weiteren Prozess brauchbar bleiben. Der zweite Schritt, die Datenstrukturierung, bedeutet, die eingehenden Daten zu sortieren und zu organisieren, so wie Lebensmittel verpackt oder zu einem Produkt zusammengestellt werden müssen. Im dritten Schritt wählen die Data Scientists jene Daten aus, die ihnen für die Analyse am wertvollsten erscheinen und beginnen mit der Ableitung ihrer Erkenntnisse – ähnlich wie die Verbraucher, die im Supermarkt Lebensmittel kaufen, um ein bestimmtes Gericht kochen zu können.
Diese sogenannte Analytics-Infrastruktur gliedert den Analyse- und Datenverbindungsfluss in verschiedene Stadien, die von deskriptiv (beschreibend) über prädiktiv (vorhersagend) bis hin zu präskriptiv (vorschreibend) reichen. Der Prozess beginnt beim operativen Reporting, wie zum Beispiel für ein regelmäßiges Vertriebsmeeting am Montagmorgen sowie weitreichendere Business Intelligence, wozu etwa integrierte Leistungsberichte und die Erstellung von KPIs oder interaktiven Dashboards zählen. Die Data Scientists kommen dann in der nächsten Phase ins Spiel: der Datenanalyse. Hier werden Beziehungen zwischen verschiedenen Datenpunkten hergestellt sowie Muster und Trends identifiziert. Die nächsten beiden Phasen des Prozesses, die Segmentierung und das Predictive Modelling, nehmen einen prädiktiven Charakter an. Kunden und Produkte werden in unterschiedliche Segmente und Gruppen unterteilt, bevor darauf aufbauend Korrelationen und Kausalzusammenhänge modelliert werden. Anschließend werden Prognosen erstellt und künftige Ergebnisse vorhergesagt. Die letzte Phase, die sich aus Simulation und Optimierung zusammensetzt, ist präskriptiver Natur. Hier werden die in früheren Phasen gesammelten Erkenntnisse in konkrete Aktionen zur Lösung einer Herausforderung überführt.
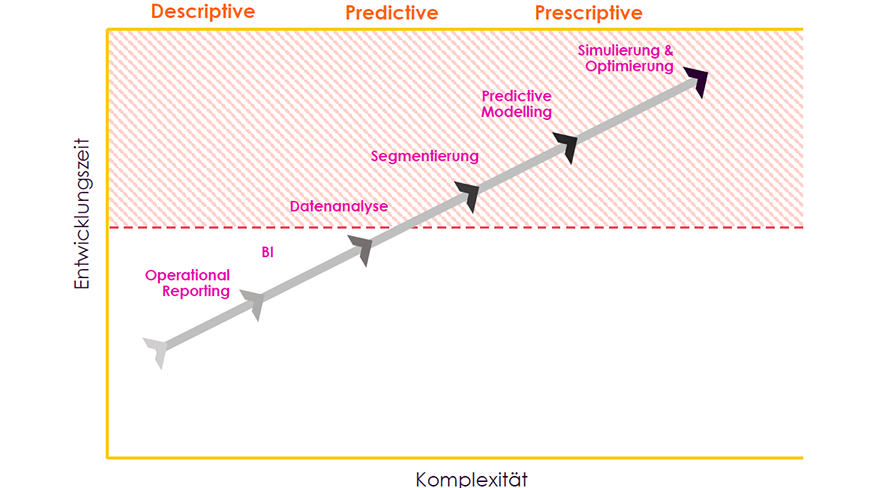
Der Daten- und Analyseverbindungsfluss wird in die Bereiche: “Descriptive” (beschreibend), “Predictive” (vorhersagend) und “Presciptive” (vorschreibend) eingeteilt.
Fallbeispiel: Die verfallenen Reservierungen
Lasst uns diesen Prozess an einem konkreten Fallbeispiel veranschaulichen: Bei MiQ trat vor einiger Zeit ein amerikanischer Autovermieter an uns heran, der das Problem hatte, dass 33 Prozent seiner Online-Reservierungen am Ende nicht zu einer tatsächlichen Anmietung des reservierten Autos führten. Der Autovermieter verlagerte also in vielen Fällen umsonst Ressourcen, um zu gewährleisten, dass das Auto zur Abholung verfügbar ist und kein anderer Kunde das gleiche Auto bucht. Das Unternehmen musste vorhersagen können, welche Kunden das reservierte Auto auch wirklich abholen würden und welche nicht.
Um dieses Ziel zu erreichen, bestand der erste Schritt darin, Informationen an verschiedenen Datenpunkten zu sammeln: Wie kamen die Kunden auf die Website des Unternehmens? Welche anderen Touch Points hatten sie mit der Marke? Wie haben sie sich online und offline verhalten? All diese Informationen wurden dann in einen einheitlichen Datensatz überführt, auf dessen Grundlage die Data Scientists ihre Analyse durchführen sollten. Im nächsten Schritt erstellten sie Entscheidungsbaum- und Lookalike-Modelle, um jene Nutzer zu identifizieren, die ihre gebuchten Autos wahrscheinlich nicht abholen würden. Auf Grundlage dieser Modelle haben wir achtzehn Faktoren identifiziert, die potenziell eine Rolle bei der Vorhersage des Kundenverhaltens spielen könnten.
Nach der weiteren Validierung dieser Analyse wurden die achtzehn Faktoren auf zwei Modelle mit zwei beziehungsweise drei Faktoren eingegrenzt. Daraus ergaben sich die folgenden Bedingungen: Wenn ein Kunde mindestens drei Änderungen an seiner Reservierung vornahm, mit einer dem Unternehmen unbekannten Kreditkarte bezahlte und den Mietwagen zu einem späteren Zeitpunkt bezahlen wollte, bestand eine 75-prozentige Wahrscheinlichkeit, dass der Kunde den Wagen nicht abholen würde. Wurde das Auto keine zwei Monate im Voraus gebucht, und gab es keine weiteren Touchpoints zum Nutzer innerhalb der ersten fünf Tage der Interaktion, betrug die Wahrscheinlichkeit, dass er seiner Reservierung nicht nachkommen würde, sogar 88 Prozent.
Dieses Fallbeispiel verdeutlicht die Bedeutung, einen integrierten Datenansatz zu fahren, um tiefergehende Erkenntnisse mit materieller Auswirkung auf Geschäftsergebnisse zum Vorschein zu bringen. Ob es einer Anreicherung von Kundendaten oder, wie im obigen Fallbeispiel, eine Verbindung von Online- und Offline-Daten bedarf, muss immer fallbedingt entschieden werden. Am besten fängt man mit einem Data Audit, also einer Prüfung des bestehenden Datenbestandes, an. Die Vorteile einer erfolgreich umgesetzten Datenkonnektivität – mit starker Infrastruktur, gut fließenden Datenprozessen und dem richtigen Know-how – liegen auf der Hand, sie gehen nämlich weit über das reine Marketing hinaus.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





