Inhaltsverzeichnis:
Eine Data Warehouse Lösung wird zu Analysezwecken, also Data-Mining als eine Analyse Anwendung verwendet, welches die Entscheidungsfindung und Berichterstellung für Benutzer in vielen Bereichen unterstützt und vereinfacht. Data Warehouses dienen außerdem als Datenbank und Archiv, welche historische Zahlen bereitstellen, die in Betriebssystemen nicht mehr verwaltet werden. Das Data Warehouse ist also auch ein Datenlager, welches unter anderem als Datenbasis für Data-Mining Methoden dienen soll.
Warum lohnt sich ein Data Warehouse?
Ein Data Warehouse ist komplex zu erstellen und aufwändig in der Wartung. Doch das Investment lohnt sich. Folgendes hat Data Warehousing zu bieten:
- Einen zentralen Zugriffspunkt auf den kompletten Datenbestand, anstatt dass Benutzer einzeln auf Dutzenden oder sogar Hunderte von Systemen und Datenbanken zugreifen müssen
- Eine Sicherung der Datenqualität
- Einen transparenten Verlauf der gespeicherten Inhalte im Data Warehouse
- Eine Trennung zwischen den alltäglichen Betriebssystemen und Analyse Systemen aus Sicherheitsgründen
- Eine Standard-Semantik für alle Inhalte und Zahlen, zum Beispiel einheitliche Namensgebung, Codes für verschiedene Arten von Produkten, Sprachen und Währungen
Durch das Speichern eines umfassenden Datensatzes in strukturierten Beziehungen kann eine Data Warehouse Lösung auch Antworten auf eine Vielzahl komplexer wirtschaftlicher (und auch operativer) Fragen geben, wie beispielsweise:
- Wie viel Umsatz hat jede unserer Produktlinien in den letzten zehn Jahren pro Monat erzielt, aufgeschlüsselt nach Stadt und Bundesland?
- Wie hoch ist die durchschnittliche Transaktionsgröße an einem unserer Geldautomaten, aufgeschlüsselt nach Tageszeit und Gesamtvermögen der Kunden?
- Wie hoch ist die prozentuale Fluktuation der Mitarbeiter im vergangenen Jahr in Geschäften, die seit mindestens drei Jahren geöffnet sind?
- Wie viele Stunden haben diese Mitarbeiter pro Woche gearbeitet?
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenWie ist ein Data Warehouse aufgebaut?
Ein Data Warehouse kann in vielen verschiedenen Formen erstellt werden, um die Komplexität der Organisationen und Unternehmen, die sie verwenden, bestmöglich zu berücksichtigen und zu strukturieren.
Oftmals decken Open-Source-Lösungen jedoch nicht die gesamte 5-Schichten-Architektur ab also folgende: Datenquelle, Datenerfassung, Datenhaltung, Datenanalyse und Datenpräsentation. Diese Schichten müssen daher miteinander kombiniert werden, um die komplette Bereitstellung eines DWH Konzeptes zu ermöglichen.
Aber die grundlegende Architektur von einem Data Warehouse ist ziemlich einheitlich:
Zuerst werden die Rohdaten formatiert. Dieser Vorgang wird manchmal auch als Bereinigen und Normalisieren bezeichnet. Du kannst dir das wie eine Pipeline vorstellen, die die Rohdaten aus ihren Quellsystemen in das Data Warehouse verschiebt und sicherstellt, dass die Daten entsprechend benannt und formatiert sind und in genauen Beziehungen zu den übrigen gespeicherten Daten bzw. dem übrigen Datenbestand stehen.
Dies wird häufig auch Integrationsschicht in der Architektur eines Warehouses genannt und nicht unbedingt als Teil des Data Warehouses selbst angesehen.
Die formatierten Werte werden dann im Datenbestand in dem Data Warehouse selbst gespeichert. Über eine Zugriffsebene können die Tools und Anwendungen die Datenmengen dann in dem Format abrufen das ihren Anforderungen entspricht und auf der Datenbasis auswerten.
Die Architektur des Data Warehouse hat eine weitere Dimension, die die gesamte Struktur regelt: Die Metadaten.
Metadaten sind quasi „Daten über die Daten“. Die Dateningenieure und Datenwissenschaftler, die das Data Warehouse verwalten, sammeln Informationen zu Datenquellen, Namensgebung, Aktualisierungsplänen usw. Außerdem verwenden sie diese Informationen, um die Datenqualität aufrechtzuerhalten und sicherzustellen, dass die Data Warehouse Lösung seinen beabsichtigten Zweck erfüllt.
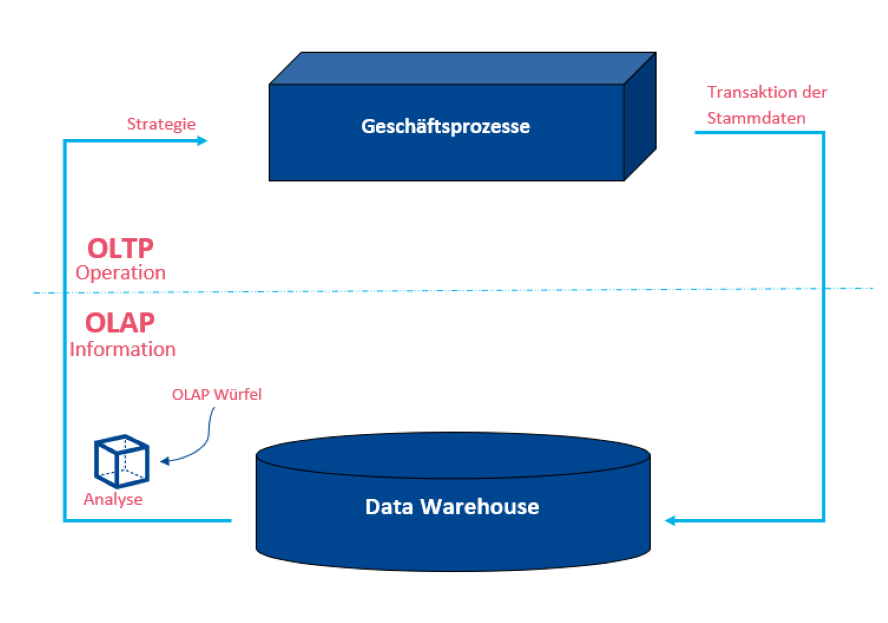
In dieser Grafik kannst Du sehen, wie Daten von dem OLTP Prozess in den OLAP Prozess übergehen. Der Analyse OLAP Würfel wird später erklärt.
Schlüsselkonzepte einer Data Warehouse Lösung: OLTP vs. OLAP
Allgemein arbeiten Datenverwaltungssysteme entweder als OLAP (Online Analytical Processing) oder OLTP (Online Transaction Processing). Generell erstellen oder erfassen OLTP-Systeme Datenmengen in Anwendungen. OLAP-Systeme analysieren Inhalte, die von einem oder mehreren Systemen erfasst wurden.
So kann eine bessere Auswertung stattfinden und ggf. werden so auch schnellere Lösungen für die ein oder andere Angelegenheit gefunden. Ein Data Warehouse ist ein Beispiel für ein OLAP-System.
Hier ist eine kurze Übersicht der Hauptunterschiede zwischen OLTP und OLAP:
OLTP:
Zweck: Unternehmensdaten/ Daten erfassen, erstellen und bereitstellen
Beispiele: Systeme, die für den Betrieb des Unternehmens benötigt werden, wie beispielsweise CRM, Finanzen usw.
Entwickelt für den effizienten Umgang mit großen Transaktionsvolumina
Speicherdauer: Kurz- oder mittelfristig; Daten des vergangenen Jahres oder der letzten paar Jahre werden in verschiedenen (operativen) Quellsystemen unterschiedlich strukturiert und im DWH einheitlich gespeichert.
Speichertyp: Optimiert für kleine Lese- und Schreibvorgänge, um den Durchsatz zu maximieren und die Wartezeit für eine Abfrage (Latenz) zu minimieren. Umfangreiche Verwendung von Indizes.
Abfrage-Typ: Liest und schreibt eine oder mehrere Zeilen.
Abfrage-Umfang: Kleine, konkrete Daten, zum Beispiel Aktualisieren der Adresse eines Kunden
Wartedauer für eine Abfrage (Latenz): 10 bis 200 Millisekunden
Datengröße: 10 GB bis 1 TB
Physischer Speicher: Zeilenorientiert – Dies bedeutet, dass ein System alle Werte in einer bestimmten Zeile scannt und verwirft, was nicht erforderlich ist. Gut zum Abrufen aller Informationen zu einem bestimmten Objekt, jedoch weniger effizient zum Ausführen von Operationen an einer Spalte für alle Zeilen in einer Tabelle.

OLAP
Zweck: Analysezwecke, Datenanalyse
Beispiele: Data Warehouses und Data Marts
Ermöglicht Analysten die effiziente Beantwortung von Fragen, für die Zahlen und Kennzahlen aus mehreren Quellen und Systemen erforderlich sind
Speicherdauer: Langfristig, in der Regel mehrere Jahre oder die gesamte Unternehmensgeschichte
Aus diesen Gründen haben OLTP- und OLAP-Systeme unterschiedliche technische Attribute und Anforderungen:
Speichertyp: Optimiert für große Lesevorgänge in umfangreichen Datensätzen und Kennzahlen. Darf keine oder nur wenige Indizes verwenden.
Abfrage-Typ: Liest meistens viele Zeilen
Abfrage-Umfang: Große Anzahl von Datensätzen, zum Beispiel der durchschnittliche Verkaufs-Wert über alle Verkäufe in den letzten 5 Jahren
Wartedauer für eine Abfrage (Latenz): 1 Sekunde bis zu mehreren Minuten
Datengröße: 1 TB bis 1PB
Physischer Speicher: Spaltenorientiert – Dies bedeutet, dass ein System alle Werte in einer bestimmten Spalte scannt. Gut für die Durchführung von Aggregationen über eine große Anzahl von Datensätzen hinweg. Weniger effizient für die Anzeige aller Attribute für ein bestimmtes Objekt (die gesamte Zeile).

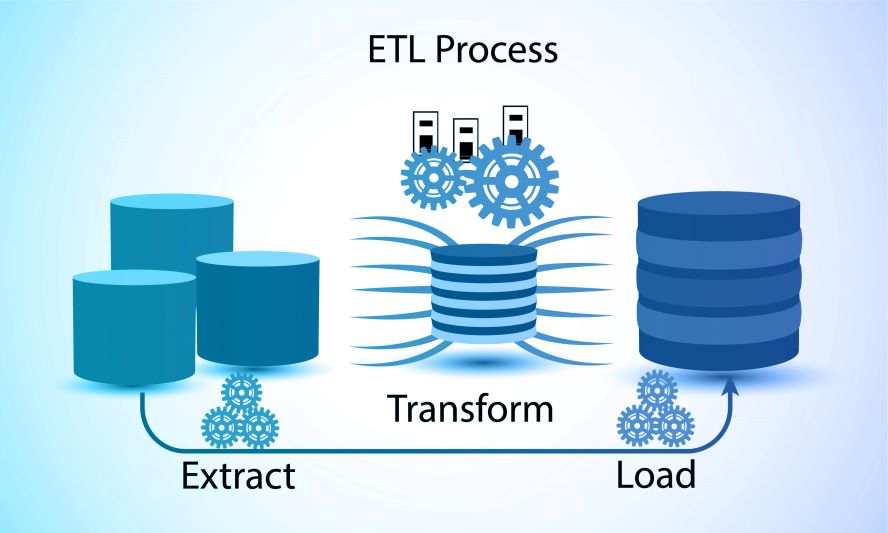
Extraktion, Transformation, Laden (ETL-Prozess)
ETL-Systeme durchlaufen einen Prozess. Sie regeln die Bewegung von Werten zwischen den Systemen von Quelldaten und einem Data Warehouse (Durch die bereits zuvor erwähnte Pipeline) sowie die Bewegung von einem Data Warehouse zu Data Marts. Die Data Marts sind subjektorientierte Datenbanken, welche für die Anforderungen beispielsweise einer Abteilung in einem Unternehmen erstellt wurden.
Im ersten Schritt im Prozess von ETL müssen die Daten zuerst aus einer Quelle extrahiert werden (Datenbeschaffung). Wenn die Extraktion auf Datenbasis stattgefunden hat, dann werden die Daten gemäß den Standards der nächsten Speicherebene transformiert. Schließlich müssen die formatierten Inhalte korrekt in diese nächste Ebene der Datenbanksysteme geladen werden, sodass sie Teil des Datenbestandes werden.
Um in der Datenhaltung aktuell zu bleiben, wird der Prozess in regelmäßigen Abständen wiederholt. Die Datenhaltung findet in der Sortierung nicht nur nach inhaltlichen Aspekten statt, sondern es findet ebenfalls eine langfristige Speicherung statt, um somit Vergleichsanalysen möglich zu machen und eine eindeutige Planungsgrundlage auf Datenbasis zu erschaffen.
Vorteile eines Data Warehouse
Nachfolgend sind einige Vorteile von Data Warehousing aufgelistet:
Ein Data Warehouse liefert erweiterte Business Intelligence.
Mit Data Warehousing-Techniken- und -Prozessen kannst Daten aus mehreren Quellen abrufen, analysieren und auswerten. Daher sind die Daten nicht auf einen bestimmten Bereich oder Abschnitt beschränkt, was Geschäftsleuten zupass kommt, um verbesserte und intelligentere Geschäftsentscheidungen zu treffen.
Das Data Warehouse und die zugehörigen Business Intelligence Prozesse können auch direkt in der Bestandsverwaltung, im Finanzmanagement, im Vertrieb und im Marketing implementiert werden.
Ein Data Warehouse gewährleistet Datenqualität und -konsistenz
Data Warehousing unterstützt die Datenkonvertierung in ein allgemeines Standardformat. Durch die Standardisierung von Daten und Ausgabe-Formen erhalten mehrere Abteilungen eines Unternehmens einheitliche Ergebnisse, ohne dass es zu Abweichungen kommt. Daher können Unternehmen mit höherer Genauigkeit und Konsistenz arbeiten und dauerhafte und verlässliche Entscheidungen treffen.
Eine Data Warehouse Lösung spart Zeit und Geld
Wenn ein Unternehmen alle Daten an einem Ort speichert, anstatt eine Vielzahl von Datenbanken zu unterhalten, spart dies dem Benutzer Zeit, auf einen bestimmten Datensatz zuzugreifen. Wichtige Entscheidungen können schneller und effizienter getroffen werden, die Mitarbeiter keine zusätzliche Zeit für die Analyse der ungeordneten Unternehmensdaten aus mehreren Quellen aufwenden müssen.
Für eine Datenabfrage in einem Data Warehouse sind keine speziellen IT-Kenntnisse erforderlich. Auch mehrere Kanälen werden für den Betrieb nicht benötigt, wodurch die Kosteneffizienz sichergestellt wird. Ein Data Warehouse ermöglicht, dass das Geschäft jederzeit und ohne Zeitverzögerung oder Abhängigkeit von externen Quellen weiterlaufen kann.
Ein Data Warehouse ermöglicht die Verfolgung historischer Daten
Da in einem Data Warehouse die historischen Daten eines Unternehmens gespeichert werden, behalten die Benutzer stets einen Überblick über die Abläufe und die Entwicklung der Geschäfte. So können Unternehmen Quelldaten in unterschiedlichen Zeiträumen verfolgen und auf Datenbasis fundierte Prognosen für die Zukunft treffen. Dies kann Unternehmen auch einen Wettbewerbsvorteil gegenüber der Konkurrenz verschaffen.
Ein Data Warehouse sorgt für einen höheren ROI (Return on Investment)
Statistisch erzielen Unternehmen, die in die Implementierung von einem Data Warehouse und zugehörigen Business Intelligence Systemen investieren, höhere Einnahmen und sparen bei jedem Geschäftsprozess bares Geld.
Nachteile eines Data Warehouse
Nach den Vorteilen nun auch ein paar Nachteile einer Data Warehouse Lösung:
Ein Data Warehouse erfordert zusätzliches Reporting
Je größer ein Unternehmen, desto mehr Daten hat es und desto größer ist der Arbeits- und Zeitaufwand für das Data Warehouse. Die durch das Data Warehouse generierten Daten erfordern die Einbeziehung aller Abteilungen des Unternehmens und erhöhen den Zeitaufwand für das Reporting. Oft handelt es sich dabei auch um Kundendaten, bei denen es zu Schwierigkeiten und Dopplungen bei der Dateneingabe kommen kann.
Ein Data Warehouse kann die Flexibilität im Umgang mit Daten einschränken
Die Vereinheitlichung und Standardisierung der Datenformate kann ein Vorteil aber gleichzeitig auch ein Nachteil von einem Data Warehouse sein. Denn es kann zu einer Übervereinfachung der Daten kommen. Dies kann es erschweren Verbindungen zwischen den Daten aufzubauen und die Abfragegeschwindigkeit verlangsamen. Ein weiteres Risiko der Standardisierung von Daten ist Datenverlust.
Ein Data Warehouse kann zu datenrechtlichen Bedenken führen
Es ist Sinn und Zweck von einem Data Warehouse, Daten an einem Ort zu zentralisieren, um die Analyse und den Zugriff bzw. die Datenbeschaffung zu vereinfachen. Dies verursacht allerdings manchmal Probleme für verschiedene Abteilungen, da sie zögern, ihre persönlichen Daten in einem zentralen System zu teilen.
Dies wirft unter Umständen auch Sicherheits- und Eigentumsbedenken in einigen Bereichen auf. In diesem Fall sollte das Unternehmen sicherstellen, dass der Datenzugriff und deren Analyse nur vertrauenswürdigen Personen im Unternehmen ermöglicht wird.
Ein Data Warehouse kann hohe Kosten verursachen
Die Implementierung von einem Data Warehouse erfordert große Mengen an Datenressourcen, um Daten aus mehreren Quellen zu verwalten und zu verarbeiten. Ein Unternehmen sollte deshalb immer das Kosten-Nutzen-Verhältnis bei der Entscheidung für oder gegen ein Data Warehouse im Blick behalten.
Verwandte Konzepte
Es folgt der Vergleich eines Data Warehouses mit verwandten Konzepten:
Data Warehouse vs. Datenbank
Genau genommen ist eine Datenbank eine strukturierte Sammlung von Daten. Eine Excel-Tabelle oder ein Adressbuch etwa wären sehr einfache Beispiele für Datenbanken. Softwares wie Excel, Oracle oder MongoDB sind ein Datenbankverwaltungssystem (DBMS), mit dem Benutzer auf die Datenbank zugreifen und diese verwalten können.
Umgangssprachlich werden die Bezeichnungen DBMS und Datenbank häufig gleichbedeutend und austauschbar verwendet. Ein Data Warehouse ist dann eine Art Datenbank. Es ist spezialisiert auf die Daten die es speichert – historische Daten aus verschiedenen Quellen – und den Zweck, dem es dient – die Analyse der Daten.
strukturiertes Data Warehouse vs. Big Data – unstrukturierter Data Lake
Ein Schlüsselmerkmal von Datenbanken und damit auch einem Data Warehouse ist, dass sie strukturierte Daten enthalten. Die Art und Weise, wie Daten gespeichert werden – von den verfügbaren Feldern über Datumsformate und diversen weitere Punkte – wird im Voraus festgelegt.
Die gesamte Datenbank folgt dann genau dieser Struktur oder diesem Schema. Aufgrund ihrer relativ einheitlichen Struktur und Stabilität können Data Warehouses Abfragen aus vielen Arten von Bereichen eines Unternehmens oder einer Organisation bedienen. Dieser Prozess ist sehr strukturiert, sehr verlässlich und sehr effizient, aber es ist eben auch nicht leicht ein Data Warehouse aufzubauen und zu pflegen.
Data Lakes sind ein weiteres Mittel zum Speichern von Daten, jedoch mit einem unstrukturiertem Schema eines Data Warehouses. Im Gegensatz zu einem Data Warehouse wird das Schema im Data Lake von der Abfrage angewendet. Dies bedeutet, dass das Laden der Daten in einen Data Lake wesentlich einfacher ist, die Erstellung von Abfragen jedoch komplexer ist. Data Lakes brauchen im Vergleich zu einem Data Warehouse normalerweise viel länger für die Bereitstellung von Ergebnissen.
Data Warehouse vs. Data Mart
Wenn ein Data Warehouse Daten aus einem Unternehmen enthält und integriert, ist ein Data Mart eine kleinere Teilmenge der Daten, die auf die Verwendung einer bestimmten Abteilung oder eines einzelnen Bereichs spezialisiert ist. Häufig werden Data Marts von einer einzigen Abteilung erstellt und gesteuert, wobei das zentrale Data Warehouse zusammen mit internen Betriebssystemen und externen Daten verwendet wird.
Data Marts umfassen normalerweise nur einen Themenbereich, zum Beispiel das Marketing oder den Vertrieb. Da sie kleiner und spezifischer sind, sind sie häufig einfacher zu verwalten und zu warten und verfügen über flexiblere Strukturen.
OLAP Cubes
OLAP Systeme enthalten häufig enorme Datenmengen, wodurch die Ausführung bestimmter Abfragen verlangsamt werden kann. Um die Abfrage zu beschleunigen und zu vereinfachen, können OLAP Systeme weiter in Unterdatenbanken unterteilt werden, die als Cubes bezeichnet werden. Diese enthalten einen begrenzten Satz von Dimensionen und bieten daher eine schnellere Abfragezeit.
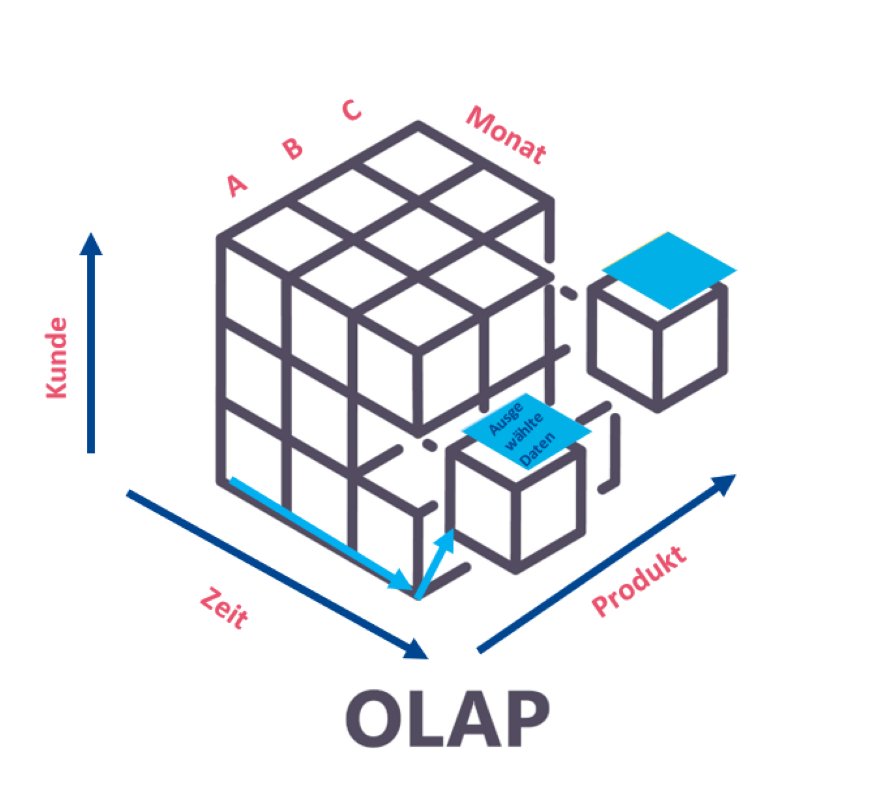
Auf diesem Bild siehst Du einen dreidimensionalen OLAP-Würfel bzw. einen Datenwürfel. Er dient zur logischen Darstellung von Daten.
Business Intelligence-Tools
Business Intelligence Software ist eine wichtige Schicht, die über einem Data Warehouse liegt. Die Business Intelligence Software erlaubt es Entscheidungen auf Basis der im Data Warehouse enthaltenen Informationen zu treffen. Business Intelligence Software verfügt über viele verschiedene Arten von Funktionen. Normalerweise enthält sie eine Art “Motor” zum Erstellen und Ausführen von Abfragen, sowie eine Möglichkeit zum Speichern und Visualisieren von Ergebnissen für die Einbindung in Dokumente, die Geschäftsanalysen enthalten.
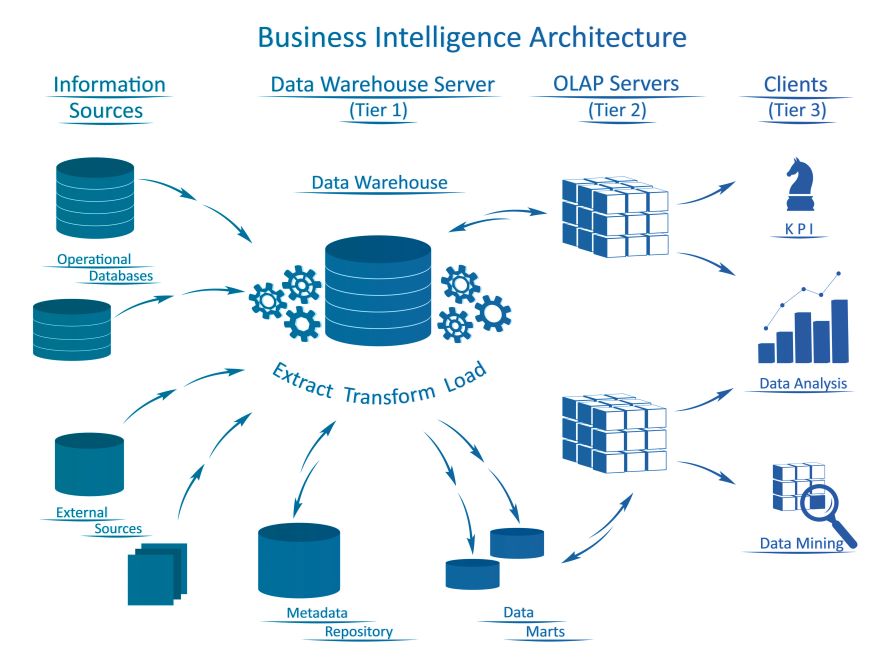
Data Warehouse Technologien
Wenn Du entscheiden musst, welche Tools und Anwendungen verwendet werden sollen, solltest du sicherstellen, dass sie deinen Anforderungen hinsichtlich Skalierbarkeit (kann sie mit deinen Anforderungen wachsen), Datenzugriff (welche Benutzer und wie viele Benutzer benötigen Zugriff auf dein Data Warehouse und von welchen Standorten aus) und Kompatibilität entsprechen (lässt sich dieses Data Warehouse System in deine Datenquellen und Business Intelligence Tools integrieren?)
Relationale Datenbanksysteme (Relationen Databases)
Relationale Datenbanken sind die Systeme, in denen die meisten Geschäftsdaten gespeichert sind. Sie existieren seit mehreren Jahrzehnten und sind sehr ausgereift. Auch für OLTP- und OLAP-Anwendungsfälle gibt es relationale Datenbanksysteme. Sie sind sehr übersichtlich und bieten umfangreiche Ökosysteme verwandter Technologien für die Verwaltung und den Datenzugriff.
MPP-Analysedatenbanken (Massively Parallel Processing)
Unter MPP-Datenbanken versteht man eine Data Warehouse Technologie, die sich auf Hardware und Software konzentriert, um die parallele Verarbeitung zu unterstützen. Das heißt, die Abfrageverarbeitung ist in viele kleinere parallele Aufgaben unterteilt, die zusammen auf mehreren Servern ausgeführt werden.
Dieser Ansatz beschleunigt die Abfrage- und Aufnahmezeiten erheblich. MPP-Datenbanken können jedoch teuer sein, da die meisten Anbieter nur Closed Source Produkte anbieten.
Hadoop
Ähnlich wie beim MPP-Ansatz kann Hadoop ebenfalls Rechenaufgaben auf einen Computercluster verteilen. Hadoop ist jedoch Open Source. Einige Data Lakes verwenden Hadoop aufgrund seiner Fähigkeit, große Mengen strukturierter und unstrukturierter Daten kostengünstig und schnell zu verarbeiten.

Fazit zu Data Warehouse Lösungen
Jedes Unternehmen verwaltet ein DWH, um die Geschichte seines Geschäfts zu erfassen. Häufig wird eine Data Warehouse Lösung auch zur allgemeinen Analyse mit anschließender Auswertung eingesetzt, da es das einzige verfügbare Tool/ Anwendung ist. Ein Data Warehouse ist leistungsstark und nützlich, erfordert jedoch sowohl im Voraus, während des Aufbaus als auch kontinuierlich, bei der Wartung und Pflege, viel Aufwand.
Zusammenfassend ist ein DWH in 3 Phasen aufgebaut: Datenbeschaffung und Datenintegration, Datenhaltung und Datenauswertung und -analyse.
Es gibt immer mehr Unternehmen auf dem Markt, welche DWH Lösungen nutzen, indem sie Datenintegration über die Cloud verwenden. Die Cloud bietet einige Vorteile wie beispielsweise eine Verfügbarkeit über das Datenlager von überall und jeder Zeit. Diese Variante ist wesentlich günstiger, allerdings kann eine Cloud aus datenschutzrechtlichen Gründen auch gefährlich sein.
Da ein Data Warehouse zentralisiert und standardisiert werden muss, um von Benutzern mit unterschiedlichen Ansprüchen und aus unterschiedlichen Bereichen eines Unternehmen sinnvoll genutzt werden zu können, enthalten sie immer Annahmen darüber, was und wie gespeichert werden soll, was nicht für alle Benutzer die optimale Lösung sein kann.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





